南佛罗里达大学的一位助理教授最近与人合著的一项研究表明,即使是语言学专家也很难区分人工智能撰写的文章和人类撰写的文章。这项发表在《应用语言学研究方法》(Research Methods in Applied Linguistics)杂志上的研究结果表明,来自全球顶级期刊的语言学专家只有约39%的时间能够准确区分人工智能和人类撰写的摘要。
研究显示,语言学专家很难区分人工智能和人类生成的文章,正面识别率仅为 38.9%。尽管他们的选择背后有逻辑推理,但却经常出现错误,这表明人工智能生成的简短文本也可以像人类写作一样胜任。

南加大世界语言系学者马修-凯斯勒(Matthew Kessler)说:”我们认为,如果有人能够识别人类撰写的文章,那就应该是语言学家,他们的职业生涯一直在研究语言模式和人类交流的其他方面。”
凯斯勒与孟菲斯大学应用语言学助理教授埃利奥特-卡萨尔(J. Elliott Casal)合作,让 72 位语言学专家审查各种研究摘要,以确定它们是由人工智能还是人类撰写的。
每位专家被要求审查四份写作样本。没有人能够正确识别所有四个样本,而有 13% 的人则全部弄错了。凯斯勒得出结论说,根据研究结果,如果没有尚未开发出来的软件帮助,教授们将无法区分学生自己的写作或由人工智能驱动的语言模型(如 ChatGPT)生成的写作。
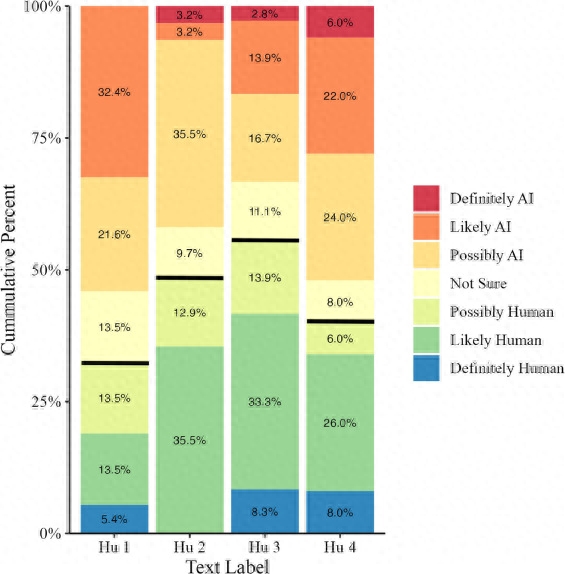
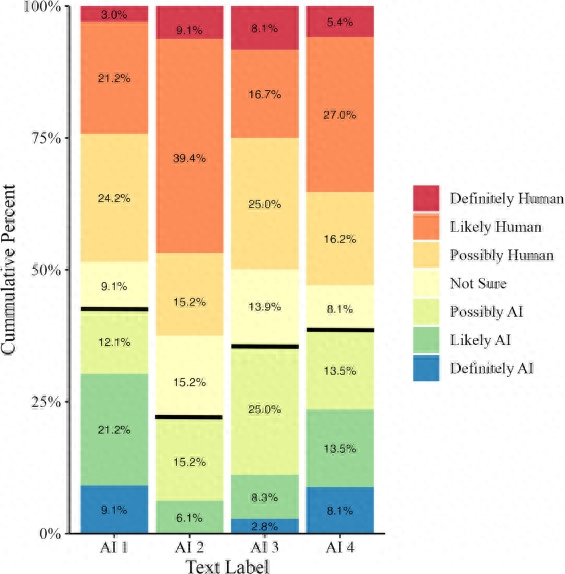
尽管专家们在研究中尝试使用理由来判断写作样本,比如识别某些语言和文体特征,但他们基本上都没有成功,总体正面识别率为 38.9%。
凯斯勒说:”更有趣的是,当我们问他们为什么要判定某篇文章是人工智能写的还是人类写的。他们分享了非常合乎逻辑的理由,但这些理由并不准确,也不一致”。
在此基础上,凯斯勒和卡萨尔得出结论:鉴于人工智能通常不会出现语法错误,ChatGPT 可以像大多数人类一样写出短篇体裁的文章,甚至在某些情况下会写得更好。
对于人类作者来说,长篇写作才是一线希望。凯斯勒说:”众所周知,对于较长的文本,人工智能会产生幻觉,编造内容,从而更容易识别出这是人工智能生成的。”
凯斯勒希望这项研究能引发更广泛的讨论,围绕在研究和教育中使用人工智能制定必要的道德规范和准则。