IT之家 9 月 3 日消息,Triton 是一种类似于 Python 的开源编程语言,它可以使没有 CUDA 经验的研究人员顺利编写高效的 GPU 代码(可以理解为简化版 CUDA),而且号称小白也可以写出与专业人士相媲美的代码,就是让用户用相对较少的努力实现最高的硬件性能,但 Triton 初期只支持英伟达 GPU。
OpenAI 声称:Triton 只要 25 行代码,就能在 FP16 矩阵乘法上达到与 cuBLAS 相当的性能。
从 Github 我们可以看到,OpenAI 已经开始在最新的 Triton 版本中合并 AMD ROCm 相关分支代码,暴露了很多此前努力的工作。也就是说,最新 Triton 后端已适配 AMD 平台,可谓意义重大。
通过官方的说法来看,他们已经通过了“test_core.py”上的大多数单元测试环节,但由于各种原因跳过了一些测试。
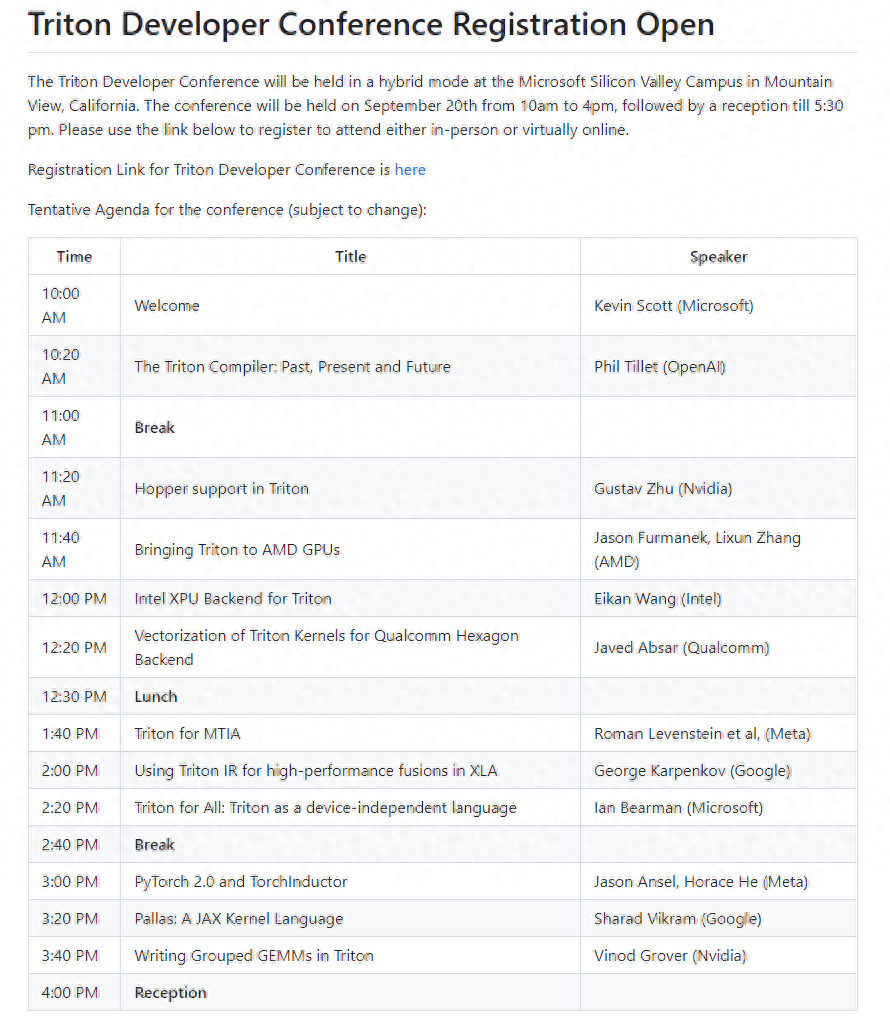
IT之家注意到,OpenAI 还宣布将于 9 月 20 日上午 10 点至下午 4 点在加利福尼亚州山景城的微软硅谷园区举行 Triton 开发者大会,而日程安排中就包括“将 Triton 引入 AMD GPU”和“Triton 的英特尔 XPU”,预计很快就会摆脱英伟达 CUDA 垄断的历史了。
值得一提的是,Triton 是开源的,比起闭源的 CUDA,其他硬件加速器能直接集成到 Triton 中,大大减少了为新硬件建立 AI 编译器栈的时间。
在此前发布的 PyTorch 2.0 版本中,TorchInductor 便引入了 OpenAI Triton 支持,可为多个加速器和后端自动生成快速代码,同时实现用 Python 取代 CUDA 编程来写底层硬件的代码。也就是说,Triton 已经是 PyTorch 2.0 后端编译器关键构成部分。
实际上,此前 AMD ROCm 则主要是采用 Hipify 工具实现 CUDA 兼容,而随着 AMD 开始为 RDNA 3 消费级显卡提供 ROCm 支持,预计后续将会有更多平台选择适配 AMD 硬件。