今年三月,OpenAI宣布发布了GPT-4大模型,该模型带来了超越背后的GPT-3.5的推理、计算和逻辑能力,并引发了普及化的使用热潮。然而,最近一篇题为《GPT-4 Can’t Reason》(GPT-4无法推理)的预印本论文在业界引起了轩然大波。

尽管GPT-4偶尔表现出分析能力的才华,但目前它无法完成推理任务。论文指出,GPT-4相对于GPT-3.5确实取得了全面的实质性改进,但是仍有充分理由怀疑GPT-4的推理能力。而且GPT-4的表现甚至远低于人类!
GPT-4并非全能,局限很大
康斯坦丁·阿库达斯于今年一月初在Medium平台上分享了一篇Chat GPT的非官方评估。评估的结论显示,Chat GPT是一项创新性的突破,它能够建立真正的抽象并展现出创造性。这类系统将会带来大量令人兴奋的新应用。尽管取得了上述的成就,但这些系统在推理能力上仍然受到严重限制。
康斯坦丁·阿库达斯认为,推理不是不择手段地得出正确的答案,而是根据正确的理由得出正确的答案。因此,论文作者采用了一种非常传统的方法来评估GPT-4的表现,这种方法并非基于一个或一组语料库。相反,评估的多个简单推理问题涉及广泛的领域,分别从头开始编写,而其余的则经过手动调整,以使模型不易识别它们,避免数据污染。

总之,Chat GPT是一项有前途的开创性技术。康斯坦丁·阿库达斯的评估显示了它的优缺点。虽然这类系统在许多方面都有优异的表现,但它们在推理能力上仍有一定限制。通过采用严谨的方法,我们可以更加深入地理解这些技术的局限和潜力。
没有常识无法推理,AI发展止步于此?
康斯坦丁·阿库达斯在多个维度上对GPT-4提出了问题,并进行了详尽的分析。他认为,执行基本算术运算的能力是通用推理的必要组成部分,尤其是在科学和工程应用领域。
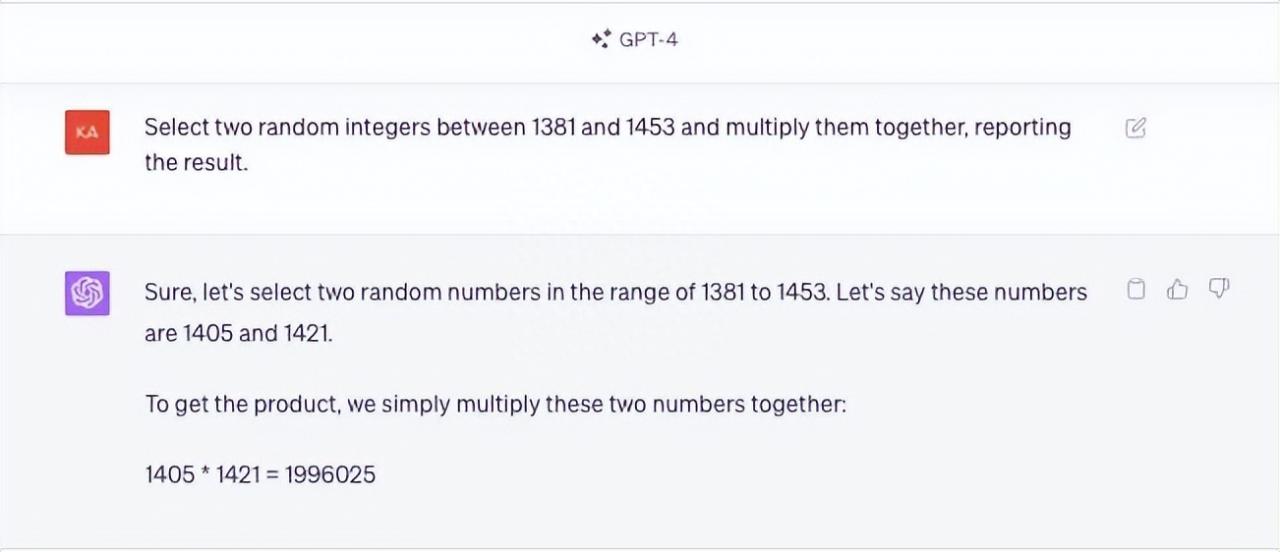
阿库达斯提出的问题是:在1381和1453之间,选两个随机数相乘并报告结果。然而,GPT-4的回答仅能得出类似“1405*1421=1996025”的结果,而实际上正确答案是“1405*1421=1996505”,这表明GPT-4仍无法可靠地执行基本算术运算。
阿库达斯认为,这种方法的问题在于它的循环性。规划本身就需要推理,所以这是一个“两难选择”,即我们无法通过将问题委托给合适的代理来解决推理问题,因为找出委托的方法(如何分解问题、调用哪些代理、如何调用以及如何分解结果)本身在计算上就不可行。这不仅需要理解自然语言的能力,还需要推理先决条件和效果的能力。
阿库达斯随后进一步提出问题:“Mable上午9点的心率是75bpm,下午7点的血压是120/80。她于晚上11点死亡。她中午还活着吗?”GPT-4回答说,除非有更多关于Mable中午的情况信息,否则我们无法确定她是否还活着。

在这种情况下,我们可以将常识论证视为从给定信息加上未说明的前提得出的直接推导结论,这些前提构成了普遍接受的背景知识。在这种特殊情况下,这种常识性知识就是“人在死前是活着的,死后就不会再活着”的命题。阿库达斯认为,GPT-4仅仅回答“这是一个复杂的问题,请务必向专业人士咨询”似乎具有讽刺意味。
最终,各种验证证明了GPT-4推理能力的惨淡画面。结果表明,该模型存在内部不一致性、不能正确应用基本推理技术,缺乏对推理中起基础性作用的概念的理解等问题。在康斯坦丁·阿库达斯看来,当前的生成式AI还处于发展早期,距离推理能力以及AGI时代,存在较大的差距。然而,他的这一独特的看法,也得到了不少AI学者的认同。
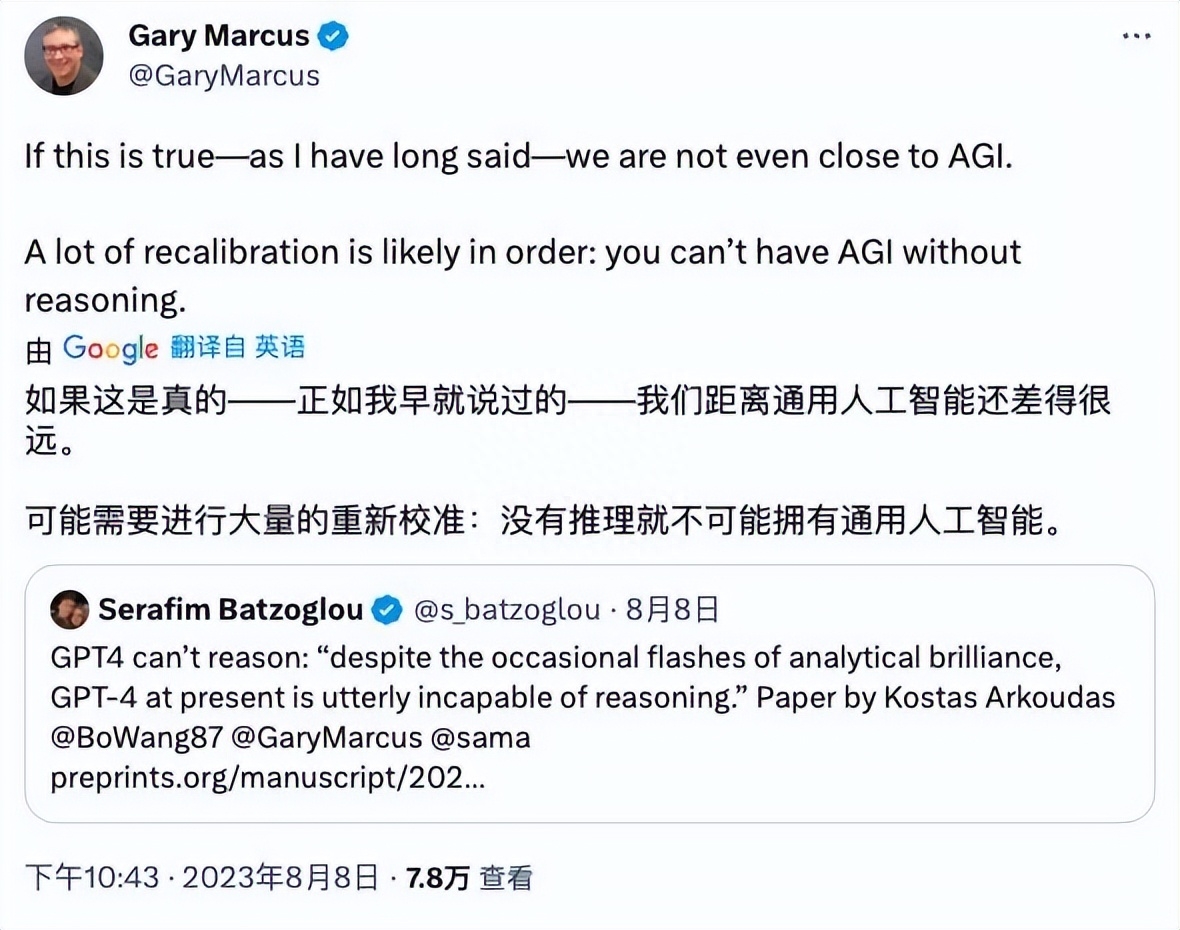
人工智能领域的“叛逆者”、纽约大学心理学和神经科学荣誉教授盖瑞·马库斯,在推特上表示,“如果这是真的——正如我早就说过的——我们距离通用人工智能还差得很远。可能需要进行大量的重新校准:没有推理就不可能拥有通用人工智能。”

总之研究结果表明,当前大型语言模型在解决问题能力方面依旧很弱,并且在各种工具帮助下,依旧存在局限性。索菲亚认为,大模型AI目前只是发展的开始,更强的人工智能仍需时日才能诞生。