在近日举办的微软开发者大会 Microsoft Build 2023 上,OpenAI 联合创始人 Andrej Karpathy 做了一个题为《State of GPT》演讲,其中他首先直观地介绍了 GPT 的训练流程的各个阶段,然后展示了如何使用 GPT 来完成任务并给出了直观的示例,最后他还给出了一些非常具有实际意义的使用建议。机器之心详细整理了该演讲,以飨读者。

视频地址:
https://youtu.be/bZQun8Y4L2A
如何训练 GPT?
首先,我们概括性地看看 GPT 大模型的训练流程。要记住,这是个新领域,变化很快。现在的流程是这样,以后新技术出现时可能会不一样。

可以看到,GPT 的训练流程可粗略分为四个阶段:预训练、监督式微调、奖励建模、强化学习。
这四个阶段按顺序进行。每个阶段都有各自的数据集,每个阶段也有各自用于训练神经网络的算法。第三行是所得到的模型。最后底部有一些备注信息。
在所有阶段中,预训练阶段所需的计算量是最大的,可以说 99% 的训练计算时间和浮点运算量都集中在这个阶段。因为这一阶段需要处理超大规模的互联网数据集,可能需要数千 GPU 构成的超级计算机工作几个月时间。其它三个阶段都算是微调(fine tuning)阶段,所需的 GPU 数量和训练时间都少得多。
下面我们将分阶段详解 GPT 的整个训练流程。
预训练阶段
预训练阶段的目标是得到一个基础模型。
首先第一步:数据收集。这一阶段需要海量的数据,下面给出了一个例子,这是来自 Meta 的 LLaMA 模型的数据混合(data mixture)方法:
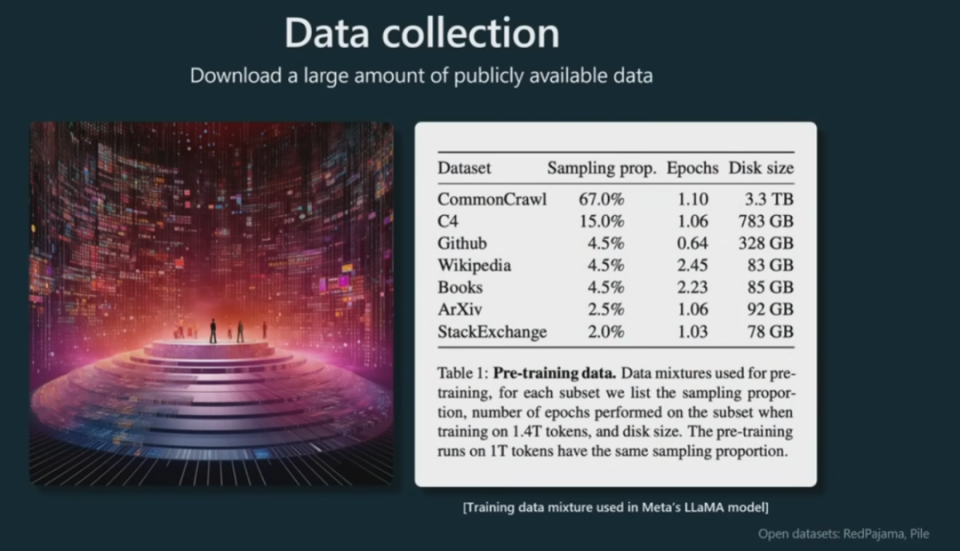
可以看到,LLaMA 的预训练数据按不同比例混用了多个不同类型的数据集,其中比例最大的是爬取自互联网的 CommonCrawl 以及基于 CommonCrawl 构建的 C4,此外还有 GitHub、维基百科等数据集。
收集到这些数据之后,还需要对它们进行预处理,这一步也被称为「token 化」。简单来说,这就是一个转译过程,即把原始文本转译成某种整数序列,因为这种整数序列就是 GPT 实际工作时所操作的本地表征。

这种从文本到 token 和整数的转译过程是无损的,而具体执行这一过程的算法有好几种。举个例子,如上图所示,我们可以使用一种名为字节对编码(byte pair encoding)的技术,其工作方式是迭代式地合并短文本块并将它们分组成 token。最后实际输入 Transformer 的就是那些整数序列。
下面来看两个示例模型 GPT-3 和 LLaMA 在预训练阶段需要考虑的一些主要的超参数。Karpathy 表示由于他们还没有发布有关 GPT-4 的相关信息,因此在演讲中使用了 GPT-3 的数据。
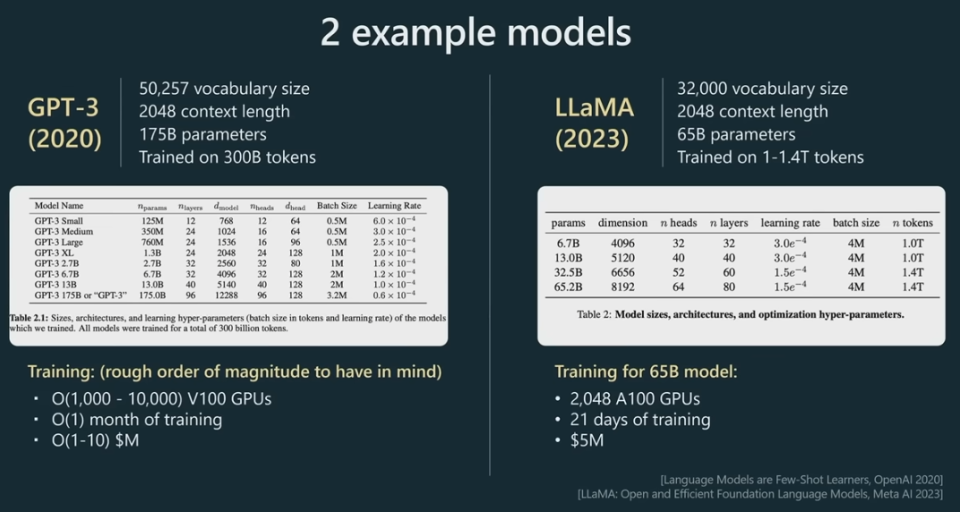
可以看到,词汇库的大小通常是 10000 数量级的;上下文长度通常为 2000 或 4000 左右,而现在更是有长达 10 万的。上下文长度决定着 GPT 在预测序列的下一个整数时所查看的最大整数数量。
对于参数数量,可以看到 GPT-3 的为 1750 亿,而 LLaMA 的为 650 亿,但实际上 LLaMA 的性能表现远胜于 GPT-3。原因何在?因为 LLaMA 训练的 token 要长得多,达到了 1.4 万亿,而 GPT-3 仅有大约 3000 亿。因此,评价一个模型时,光看参数数量是不够的。
上图中部的表格中给出了 Transformer 神经网络中一些需要设定的超参数,比如头的数量、维度大小、学习率、层数等等。
下方则是一些训练超参数;比如为了训练 650 亿参数的 LLaMA 模型,Meta 使用 2000 个 GPU 训练了大约 21 天,资金成本大约为 500 万美元。这大概能体现出预训练阶段各项成本的数量级。
接下来看实际的预训练过程究竟会发生什么。大致来说,首先会把 token 分批组成 data batch。这些分配数据构成数组,再被输入到 Transformer 中。这些数组的大小为 B×T;其中 B 是分批大小,即堆叠的独立样本的行数;T 是最大上下文长度。下图给出了一个示例。

在图中示例中,上下文长度 T 仅为 10,但实际模型的 T 可达到 2000 或 4000 乃至更长。也就是说,实际模型的一行数据可以非常长,比如一整个文档。我们可以将许多文档打包到各行中,并用这些特殊的文本结束 token <|endoftext|> 来分隔它们。简单来说,这些 token 是告诉 Transformer 新文档开始的位置。比如图中的 4 行文档就转换成了底部的 4×10 的数组。
现在,需要将这些数字输入到 Transformer。这里我们仅看其中一个单元格(绿色),而实际上每个单元格都会经历同样的处理流程。
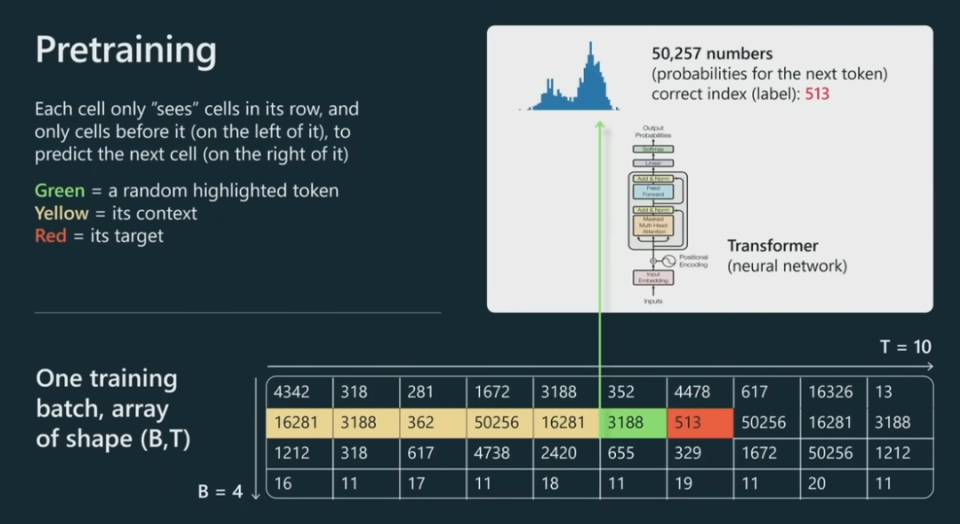
这个绿色单元格会查看其之前的所有 token,即所有黄色单元格的 token。我们要将这里的全部上文输入到 Transformer 神经网络,Transformer 则需要预测出该序列的下一个 token,即图中的红色 token。
为了给出准确的预测,神经网络需要调整其上百亿个参数。每次调整后,神经网络对每个单元格 token 的预测分布就会不同。举个例子,如果词汇库的大小为 50257 个 token,那么我们就需要同样多的数字,以便得到下一个 token 的概率分布,其预测了下一个 token 的可能值及相应概率。
在图中的示例中,下一个单元格应该是 513,因此就可以将其用作监督源来更新 Transformer 的权重。我们可以并行地对每个单元格采取同样的操作。我们不断更换数据批,努力让 Transformer 有能力正确地预测序列的下一个 token。
下面再看一个更具体的示例。这是《纽约时报》用莎士比亚作品训练的一个小型 GPT。这里给出了莎士比亚作品中的一小段以及在其上训练 GPT 的情况。
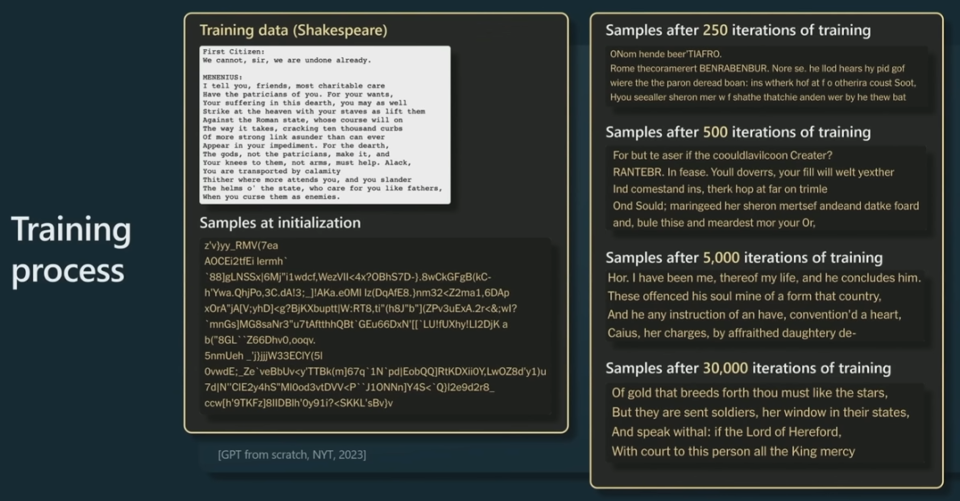
首先,在 GPT 初始化时,权重是完全随机的,所以其输出结果也是完全随机的。随着时间推移,训练时间越来越长,GPT 不断迭代,模型给出的结果样本也就越来越连贯通顺了。最后,可以看到 Transformer 学到了一些有关词的东西,也知道应该在哪些地方放置空格了。
在实际预训练过程中,要通过一些量化指标来确定模型迭代中的表现变化。一般来说,研究者监测是损失函数。损失低说明 Transformer 更可能给出正确预测,即序列中下一个整数是正确值的概率更高。
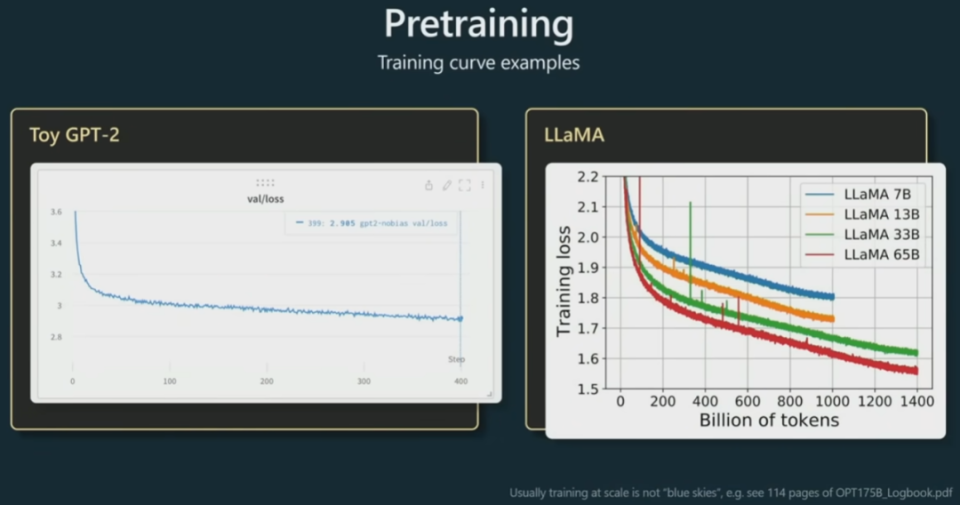
预训练其实就是一个语言建模过程,这个过程的训练时间可长达一个月。之后,GPT 学到了一个非常强大的通用型语言表征。然后我们可以针对具体的下游任务高效地对其进行微调。
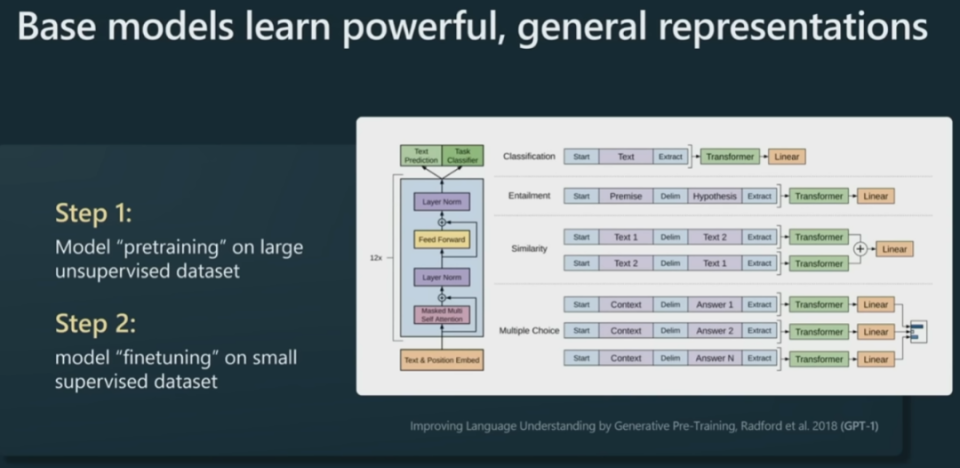
举个例子,如果下游任务是情绪分类。过去,你采用的方法可能是收集大量标注好「正面」或「负面」情绪的样本,然后训练一个 NLP 模型。但现在的新方法不需要预先做情绪分类了,你只需要拿一个预训练过的大型语言模型,然后只需要少量示例样本,就能非常高效地针对你的具体任务对模型进行微调。
这对实际应用来说非常有用。那么为什么预训练后的大型语言模型(LLM)只需要简单微调就能用呢?这是因为语言建模过程本身就已经涵盖了大量任务 —— 模型为了预测下一个 token,必须理解文本的结构以及其中内含的各种不同概念。