梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
自动测试分数达到ChatGPT的99.3%,人类难以分辨两者的回答……
这是开源大模型最新成果,来自羊驼家族的又一重磅成员——华盛顿大学原驼(Guanaco)。

更关键的是,与原驼一起提出的新方法QLoRA把微调大模型的显存需求从>780GB降低到<48GB。
开源社区直接开始狂欢,相关论文成为24小时内关注度最高的AI论文。
以Meta的美洲驼LLaMA为基础,得到原驼650亿参数版只需要48GB显存单卡微调24小时,330亿参数版只需要24GB显存单卡微调12小时。
24GB显存,也就是一块消费级RTX3090或RTX4090显卡足以。
不少网友在测试后也表示,更喜欢它而不是ChatGPT。

英伟达科学家Jim Fan博士对此评价为:大模型小型化的又一里程碑。
先扩大规模再缩小,将成为开源AI社区的节奏。

而新的高效微调方法QLoRA迅速被开源社区接受,HuggingFace也在第一时间整合上线了相关代码。
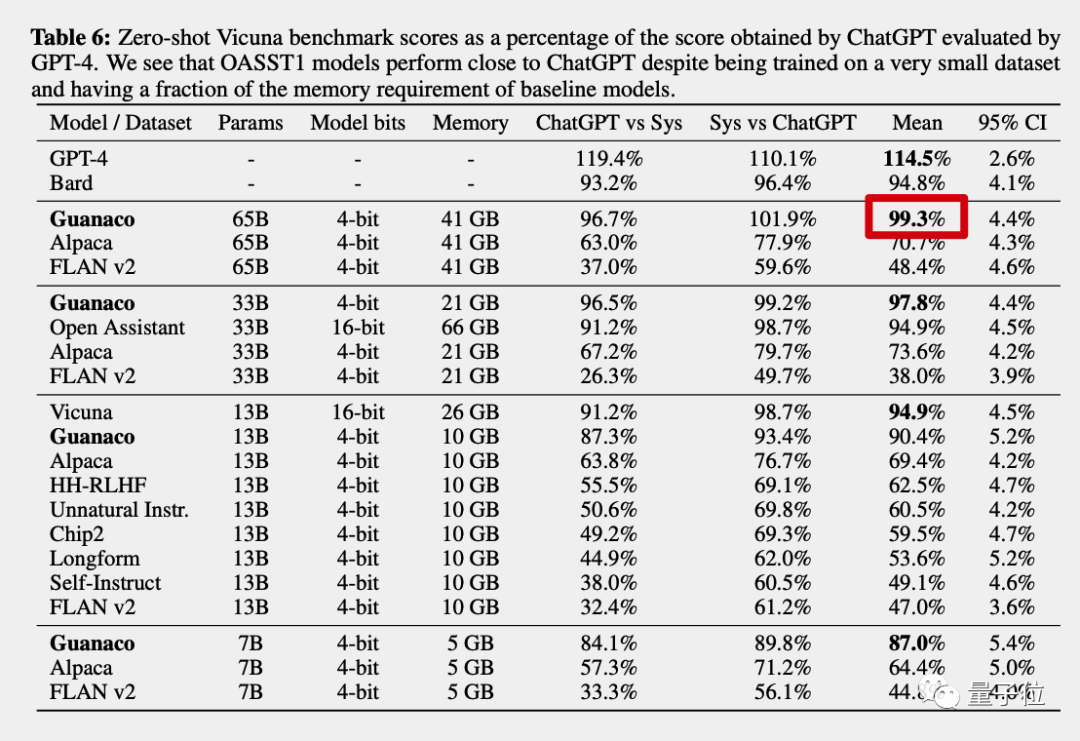
GPT-4做裁判,原驼得分达到ChatGPT的99.3%
论文中,团队对原驼总共做了三项测试,自动评估、随机匹配和人类评估。
测试数据来自小羊驼Vicuna和Open Assistant。
自动评估由大模型天花板GPT-4当裁判,对不同模型的回答进行打分,以ChatGPT(GPT3.5)的成绩作为100%。
最终原驼650亿版得分达到ChatGPT的99.3%,而GPT-4自己的得分是114.5%,谷歌Bard是94.8%。
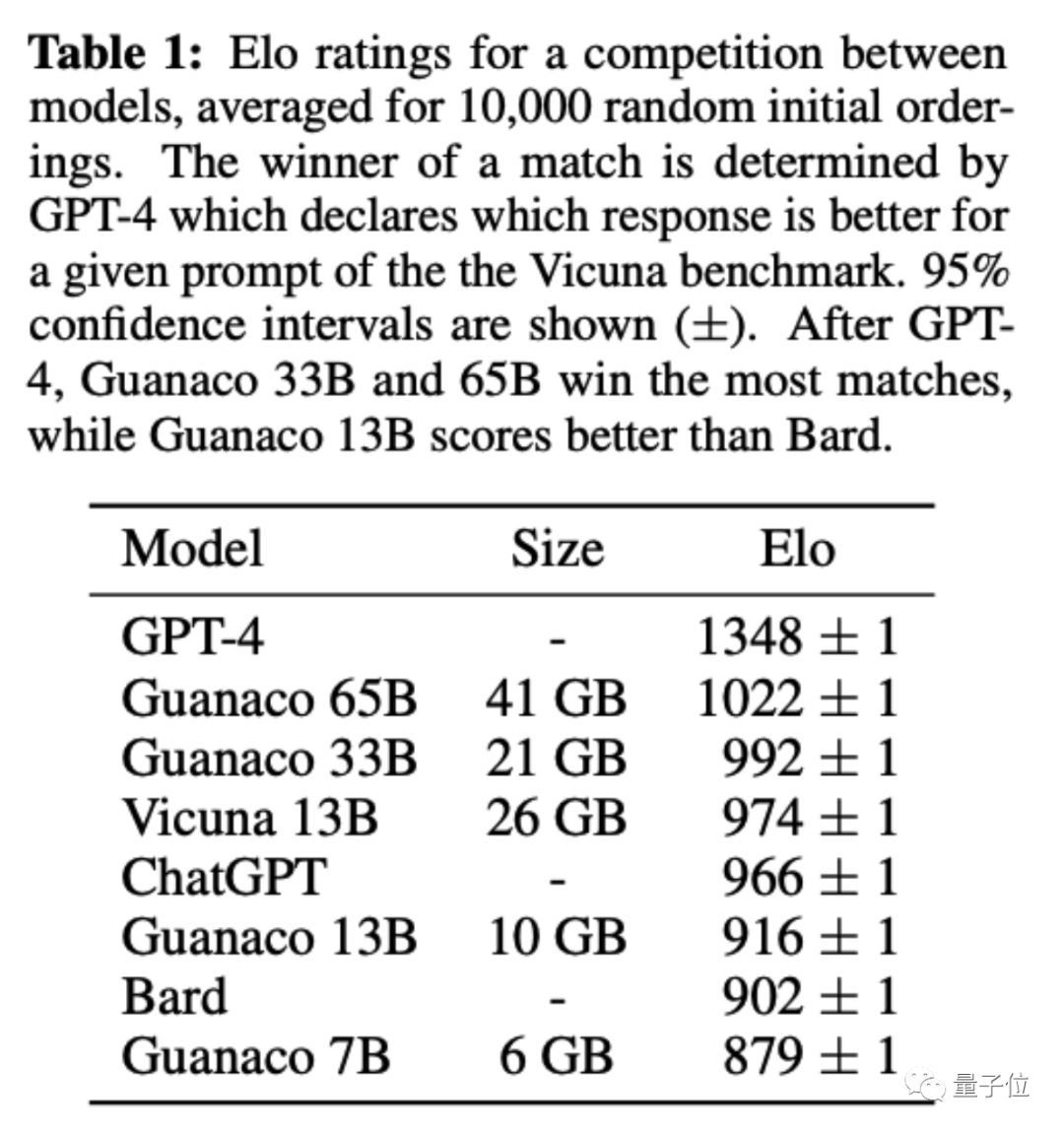
随机匹配,采用棋类专业比赛和电子竞技同款的Elo记分机制,由GPT-4和人类共同做裁判。
原驼650亿和330亿版最终得分超过ChatGPT(GPT3.5)。
人类评估,则是把原驼650亿版的回答和ChatGPT的回答匿名乱序放在一起,人类来盲选哪个最好。
论文共同一作表示,研究团队里的人都很难分辨出来,并把测试做成了一个小游戏放在Colab上,开放给大家挑战。
这里节选其中一个问题(附中文翻译),你能分辨出哪个是ChatGPT回答的吗?
问题:How can I improve my time management skills?(如何提高时间管理技能?)

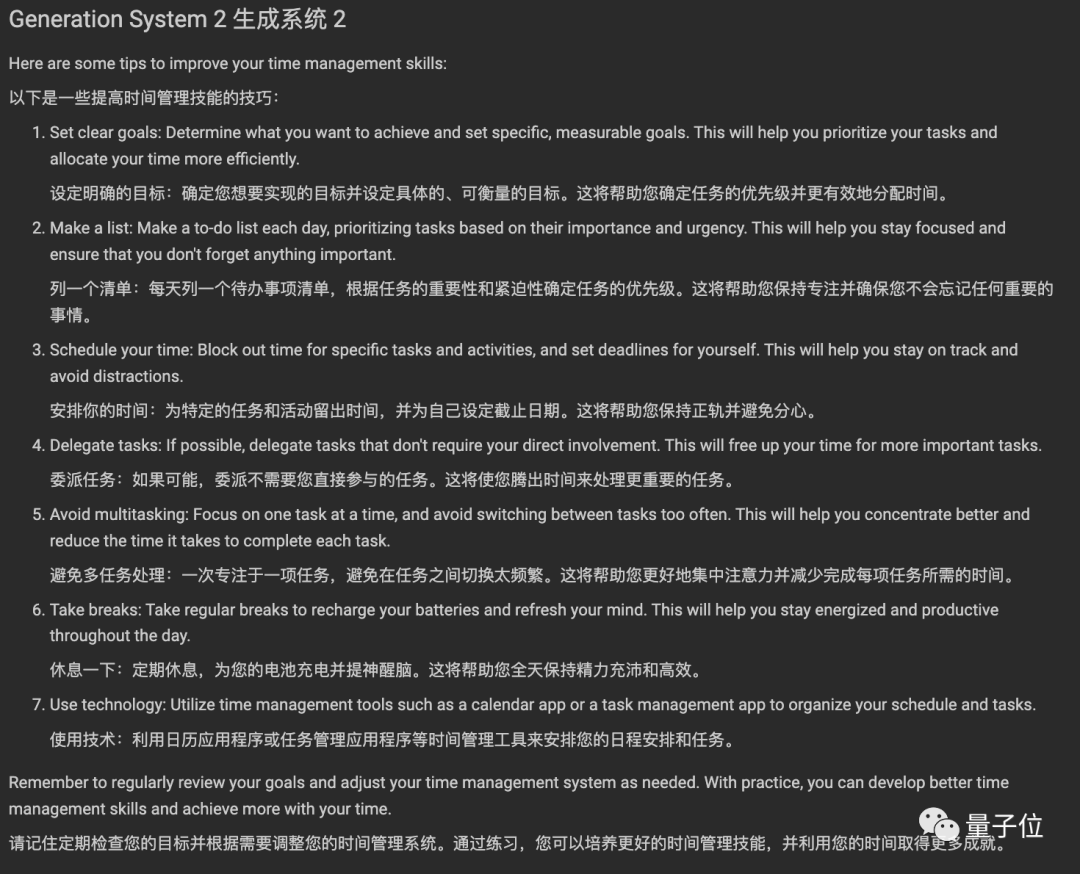
(完整测试地址在文末)
总的来说,原驼的优势在于不容易被问题中的错误信息误导,比如能指出地球从来没有被科学界认为是平的。

以及擅长心智理论(Theory of Mind),也就是能推测理解他人的心理状态。

但原驼也并非没有弱点,团队发发现它不太擅长数学,以及容易用提示注入攻击把要求保密的信息从它嘴里套出来。

也有网友表示,虽然一个模型能在某个数据集上无限接近ChatGPT,但像ChatGPT那样通用还是很难的。

全新方法QLoRA,iPhone都能微调大模型了
原驼论文的核心贡献是提出新的微调方法QLoRA。
其中Q代表量化(Quantization),用低精度数据类型去逼近神经网络中的高精度浮点数,以提高运算效率。
LoRA是微软团队在2021年提出的低秩适应(Low-Rank Adaptation)高效微调方法,LoRA后来被移植到AI绘画领域更被大众熟知,但最早其实就是用于大语言模型的。
通常来说,LoRA微调与全量微调相比效果会更差,但团队将LoRA添加到所有的线性层解决了这个问题。