自去年 11 月 ChatGPT 面向公众测试以来,OpenAI 一直占据各大科技网站的头版头条,以及成为很多开发者工具的首选。ChatGPT 的落地不仅仅可以提供代码建议、总结长文本、回答问题等等,更为重要的是它开启了 AIGC 的新时代。
不过由于 OpenAI 不再 Open 的问题,该工具在备受好评的路上也备受争议。在此背景下,一批批开源实践者在大模型维度开始了多种尝试,意欲复刻一个 ChatGPT,OpenAssistant 便是参与竞争的开源产品之一。
Open Assistant 机器学习模型是由一家德国非营利组织 LAION 运营。近日,该组织官宣现在可以使用 OpenAssistant 模型、训练数据和代码,并将该模型称之为「全球最大的 ChatGPT 开源复制品」,试用地址:https://open-assistant.io。

让人人都能通过开源的方式,用上会话 AI,已成为了现实,这也让 Open-Assistant(https://github.com/LAION-AI/Open-Assistant)在众多开源项目中脱颖而出,截至目前,收获了 24.1k 个 Star,Fork 数达 1.9k。

世界上最大的 ChatGPT 开源平替——Open Assistant
OpenAssistant 项目开始于 2022 年 12 月,彼时就是在 OpenAI 发布 ChatGPT 之后不久后。
“我们不会止步于复制 ChatGPT。我们希望构建未来的助手,不仅能够编写电子邮件和求职信,还能做有意义的工作、使用 API、动态研究信息等等,并且能够由任何人进行个性化和扩展。我们希望以一种开放和可访问的方式来做到这一点,这意味着我们不仅要构建一个出色的助手,还要使其足够小和高效以在消费类硬件上运行”,OpenAssistant 项目维护者在其 GitHub 页面上写道。
简单来看,Open Assistant 的目标是创建一个和 ChatGPT 具有相同能力的开源人工智能助手。项目维护者认为,通过这个项目,他们可以改进语言本身,类似于稳定地传播如何创造新的艺术和图像。
为此,该团队花了近五个月的时间,在 13500 多名志愿者的帮助下,收集了一个 “由人类生成的、由人类注释的助理式对话语料库,包括分布在 66497 个会话树上的 161,443 条信息,使用 35 种不同的语言,有 461,292 个质量等级的注释”。
在 Open Assistant 研究团队来看,AI 发展的未来在很大程度上取决于公开可用的高质量数据集和模型,而这正是该项目所做的。也就是在当下,他们终于可以对外公开这个非常强大的模型,现在可以在以下网址试用:open-assistant.io/chat 。
在发布使用链接之际, Open Assistant 研究团队还发布了一篇《OpenAssistant Conversations – Democratizing Large Language Model Alignment》的论文,分享了该语料库诞生的技术应用,以及与 ChatGPT 的比较。

OpenAssistant Conversation 语料库,支持 35 种语言
正如上文所述,该语料库是一个全球众包努力的产物,有超过 13,500 名志愿者参与。根据论文介绍,它的基本数据结构是一个会话树(Conversation Tree,CT),节点代表对话中的消息。一个 CT 的根节点代表一个初始提示,由提示者给出。为了避免混淆,研究人员把对话的角色称为提示者和助手。
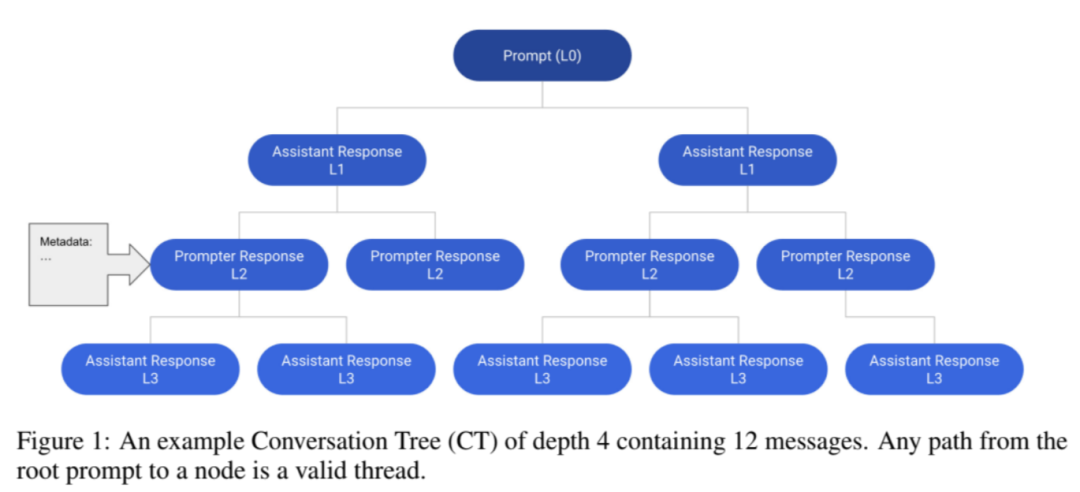
这些数据是通过一个 Web 应用程序界面收集的,该界面通过将整个流程分为五个独立的步骤来完成:提示、标记提示、作为提示者或助手添加回复信息、标记回复、以及对助手的回复进行排名。
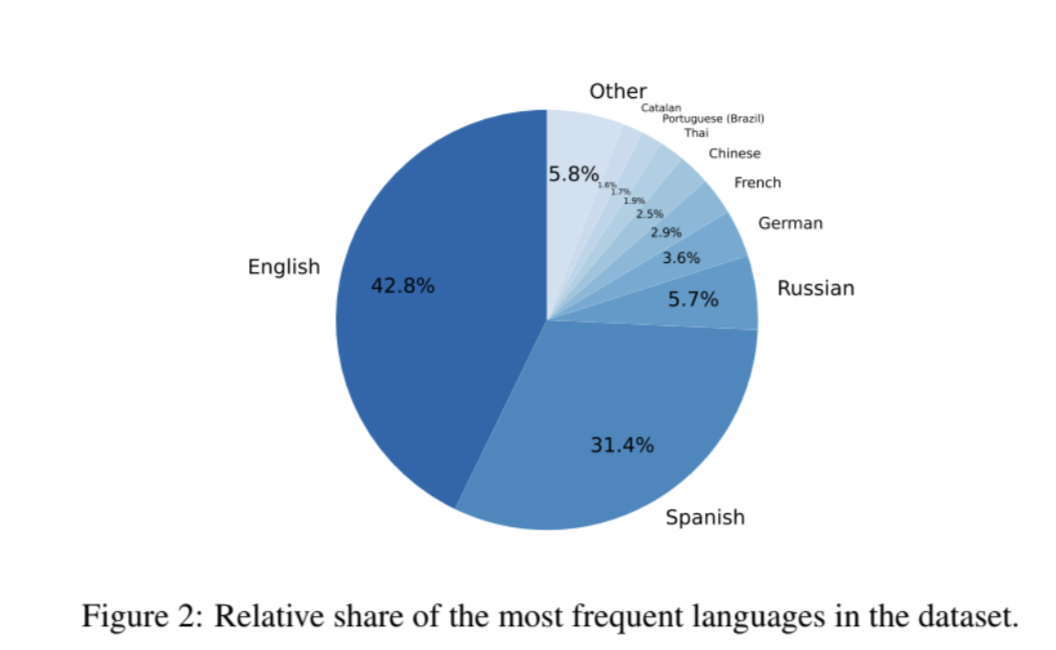
这个数据集主要以英语和西班牙语为主。根据论文介绍,英语占比较重符合预期,因为围绕 OpenAssistant 的社区起源于讲英语的开源机器学习社区。中文在此语料库中占比 2.5%。
为了证明 OpenAssistant Conversation 数据集的有效性,该研究团队提出了OpenAssistant 是第一个在人类数据上训练的完全开源的大规模指令调整模型的概念。
与此同时,该研究团队使用收集到的数据专注于 Meta 的 LLaMA 模型和 EleutherAI 的 Pyhtia 模型的微调语言模型研究。
其中,Pythia 是一个最先进的语言模型,具有宽松的开源许可,而 LLaMA 是一个强大的语言模型,具有定制的非商业许可。
对此,研究团队发布了一套微调的语言模型,包括指令调整的 Pythia-12B、LLaMA-13B 和 LLaMA-30B。
值得注意的是,最大的变体基于具有 300 亿个参数的 LLaMA 模型,这是他们迄今最大的模型。与 Alpaca 或 Vicuna 一样,这些模型是“指令调整”的,并且没有通过人类反馈强化学习 (RLHF) 进一步改进。
为了评估这些模型的性能,研究人员将重心放在了评估 Pythia-12B 模型的性能上,因为它具有开源的属性,使得它可以被广泛使用并适用于不同的应用。
研究人员还将其输出与 OpenAl 的 gpt-3.5-turbo(ChatGPT) 模型进行比较。
截至发稿时,这项研究已经获得了 348 份提交的资料,总共有 7042 项比较,结果发现:Pythia-12B 对 gpt-3.5-turbo 的胜率为 48.3%。
这一结果意味着 Pythia-12B 产生的答案与 gpt-3.5-turbo 产生的答案一样有 93.5% 的可取性,表明该研究团队微调的 Pythia 模型在大规模语言模型领域是一个强有力的竞争者。
除此之外,研究者还发布了基于 Pythia-1.4B 和 Pythia-12B 的经过训练的奖励模型。
在论文中,该团队还透露,使用谷歌搜索等插件的初步实验已经在进行中。该团队还计划在未来用 RLHF 训练和发布一个L LaMA-30B 模型。