最近,ChatGPT 迅速引爆 AIGC 领域,依托全网大数据与海量智能模型训练,一举成为 Stable Diffusion 之外的 AI 新宠。不同于过往初阶聊天机器人,这位“懂王”似乎可以取代大型搜索平台,与用户展开高质量同频对话。网友也特别乐于「调戏」它,还生成出了不少奇怪的神回复。
ChatGPT 奇特之处恰在于其『学习性』,也就是说它具备进化能力,能够在与人沟通、学习过程中变得更加聪明。在官方介绍里也提到过,它可以指出不正确前提,拒绝回答不适当问题,甚至会承认错误。

展开高智商对话的同时,ChatGPT 也能写出优雅的代码。如果你告诉他需要创建一个 PHP 程序来扫描主机名上的开放端口,就可以得到一份代码,虽然目前看来还是比较初级的,但随着后续的学习和调整,应用前景存在无限可能。
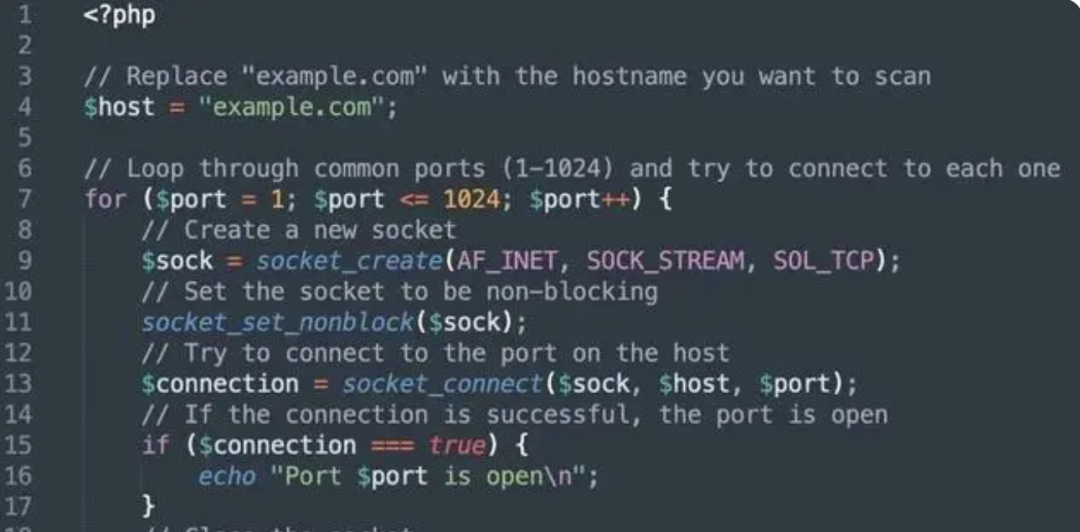
更厉害的是,它还能够在 ChatGPT 中构建虚拟机,运行 Linux 指令,甚至还可以用 curl 来让 Chat GPT 和自己做交互。
如果格局打开一点,我们是不是可以说,在跨端开发时候它可以取代election,真的有助于降本增效?尽管目前还不能做到这么高阶的玩法,但是依照 ChatGPT 的潜质,这或许只是时间问题。
当然,玩法只是表层,更值得谈论的则是其里程碑式意义:AI已然从幕后转向了台前。
在过去的两周里,ChatGPT的热度一度超过 Alpha Go 的峰值。虽然在过往,像是 AlphaGo 这类 AI 产品确实为用户所熟知,但是离用户还是太远了。而 ChatGPT 更像是「民用级」的产品,真正意义上让AI技术广泛破圈应用。
大规模模型训练、海量数据
共同成就 ChatGPT
ChatGPT 的出圈并不是偶然,透视结构,它是一种基于 InstructGPT算法架构开发的大型预训练语言模型,而在这之中,OpenAI 为这个模型新增了代码理解和生成能力,这样就可以极大的拓宽应用场景,甚至在这之中,它还加入了一些道德原则,如此就能够识别恶意信息,而且还可以拒绝回答等。在使用体验被拉满之后,我们所能够见到的就是不同于原先的、更贴近于「人」的使用感。
如果从技术角度去解读,我们不难看出,这些产品的背后,都是基于大模型、大数据的不断训练。在之前就有报道指出,ChatGPT背后的训练除了常规的万亿级别语料投喂之外,还依托于其强大的算力。
据数据披露,ChatGPT的总算力消耗约为3640PF-days。事实上这几件事我们可以认为是相辅相成的,即高质量的人工标注数据+强化学习为底层逻辑,在经过万亿级别的语料投喂后不断进行学习和迭代,最后依托于强大的算力为产品的学习和输入输出进行支撑。
看上去难吗?不难,但也很难。在过去的很长一段时间里,许多的厂商都是通过本地设备来进行训练的,甚至在过去,知乎还曾经有人提问「为什么很少有机器学习上云」。

事实上在过往有很多的公司都因为对算力的强需求被拖垮了,这也就是为什么很长一段时间内我们都很难在机器学习领域看到新的产品了。出彩的产品本身就因为算力的桎梏而变得很少,更遑论出圈的呢?
但是,当时间大跨步进入现在以后,这件事就变得截然不同了。在当下,机器学习和深度学习的上云已经相当普遍,而市面上也有很多的产品都在基于大模型的训练和推理给出更适合个人开发者和企业开发的解决方案,亚马逊云科技就是其中之一。
从高门槛到低成本,
亚马逊云科技做对了什么?
从刚刚过去不久的2022亚马逊云科技 re:Invent 全球大会上,我们可以得知ChatGPT 这类基于大模型的训练和推理,正是未来驱动机器学习发展的关键趋势之一。
首先,大模型的训练和应用门槛亟须降低。
ChatGPT 相比以往对话机器人,之所以“聪明”,是因为摄入了数以亿计的语料库内容,而如此规模的大模型的训练和应用成本极高,绝大部分企业都无法承担,但我们看到越来越多的大模型走向了开源,并允许用户在此基础上进行低成本的微调,以更加适配最终用户的业务场景。如何获取这些大模型,并快速进行部署和微调,是真正落地大模型应用需要考虑的问题。
Amazon SageMaker JumpStart简单明了的回答了这个问题,JumpStart提供了超过350个来自TensorFlow、PyTorch、Hugging Face以及MXNet等广受欢迎的模型中心所提供的最先进的预训练模型、内置算法以及预置解决方案模板,能为对象检测、文本分类和文本生成等流行的ML任务提供支持,在re:Invent 2022上,亚马逊云科技宣布将来自Stability.AI (发布了火出圈的用于AIGC的 stable diffusion模型)和 AI21 公司的大模型集成到SageMaker JumpStart,用户仅需点点鼠标,即可完成模型的部署和微调,极大的降低了大模型应用的门槛。
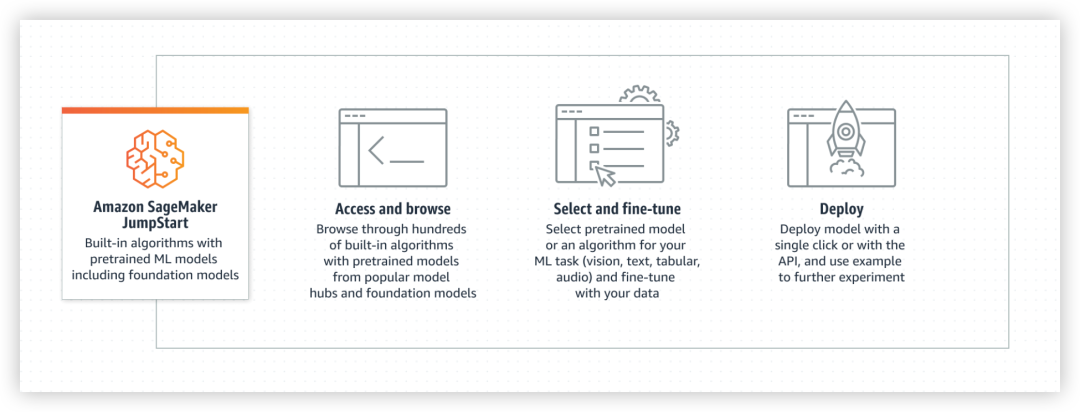
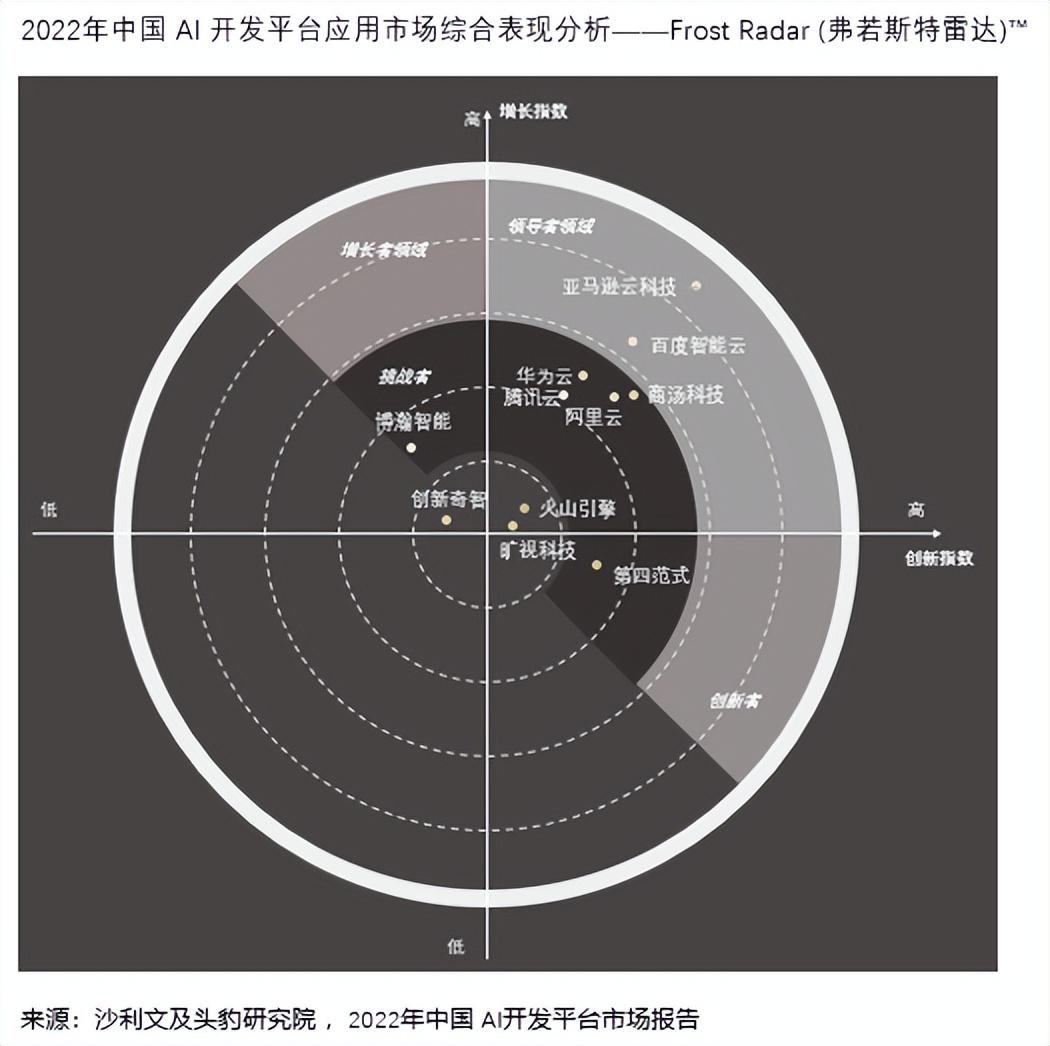
沙利文中国及头豹研究院近期发布了《2022中国 AI 开发平台报告》,亚马逊云科技连续第二年被评为中国 AI 开发平台领导者,在创新指数(横轴)和增长指数(纵轴)均位列第一,具有明显的优势。“亚马逊云科技具备完备的AI开发软硬全栈供应水平,从专用基础设施、AI平台到各类场景开箱即用的AI服务解决方案,结合亚马逊云科技的系列云上服务,满足各类型客户的不同需求”。
第二,大模型训练和推理,更需高性能芯片助力。
ChatGPT 不仅需要巨量数据源“投喂”训练模型,而且也需要强有力的算力与芯片支持,而这些都需要巨量的成本。即便是在技术水平相当理想的情况下,成本问题也很惊人。
事实上对于很多个人学习者和初创公司来说,成本都是绕不开的问题。个人学习者其实很难不因为传统云的价格而感到吃力,但是亚马逊云科技对这类问题则有了更好的解决方案。
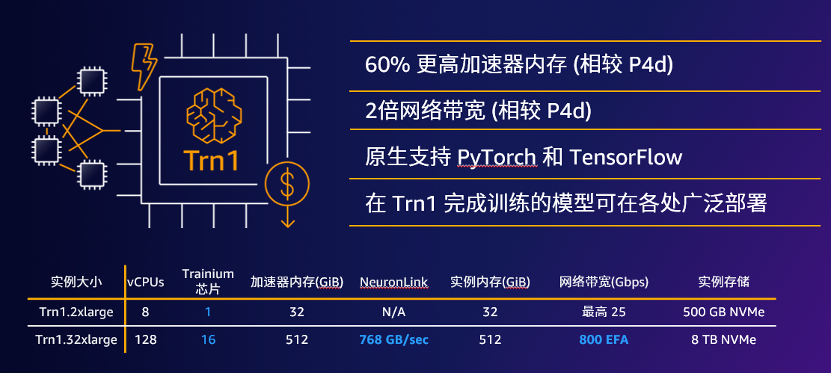
在前段时间,亚马逊云科技推出了基于 Amazon Trainium 自研芯片的 Amazon EC2 Trn1实例的高性价比解决方案,与基于 GPU 的同类实例相比,Trn1可节省高达50%的训练成本,不管是从缩短时间、快速迭代模型,还是提升训练准确率维度来说,都可以助力 ChatGPT 一类 AIGC 应用降本增效,表现更出众。
值得一提的是,使用 Trn1 实例无需最低消费承诺或预付费用,只需为使用的计算量付费,计费方式十分合理。像是 Stable Diffusion 模型的母公司 Stability AI 就在使用 Trn1 进行模型训练,持续提升生产效能。
对于大模型的推理,亚马逊云科技同样给出了答案,由第二代Amazon Inferentia 加速器支撑的Amazon EC2 Inf2实例。与第一代 Inf1 实例相比,Inf2 实例的计算性能提高了 3 倍,加速器内存提高了 4 倍,吞吐量提高了 4 倍,延迟降低了 10 倍。Inf2 实例经过优化,可以大规模部署日益复杂的模型,例如大型语言模型(LLM)等,其通过加速器之间的超高速连接可支持横向扩展分布式推理,即使是大如175B 参数模型也可以方便部署并提高高速推理。
第三,基于 NLP 大模型的服务,并非仅有 ChatGPT。
像 ChatGPT 这种基于NLP大模型的服务,亚马逊云科技也拥有多种 AI 服务。
事实上,NLP大模型的落地是很难的,因为它们普遍需要高效的分布式大模型训练和快速的在线推理服务才能够落地,所以对于绝大多数公司来说,不管是从人力成本还是其他层面上来说,都存在一定的阻碍,亚马逊云科技凭借多年云业务经验,可以在多条业务线上齐头并进,协同合作伙伴快速展开生态化创新。
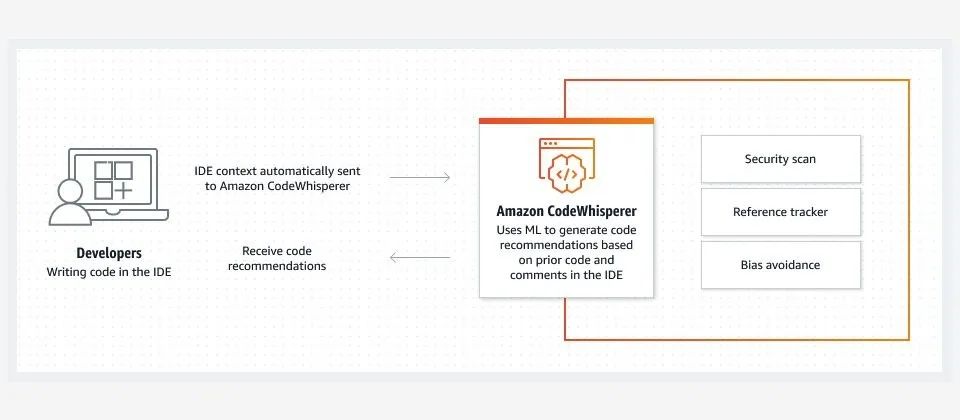
比如 CodeWhisper 就是基于机器学习的代码开发助手,能够帮助更多人来加速开发、提高生产力,除此之外还有还有大家都熟知的Alexa语音助手,也是基于包含200亿个参数的AlexaTeacher Model(AlexaTM 20B)大模型,而这些都能够切实地帮助用户进行降本增效,继而更好地享受到科技红利。
写在最后
当我们谈论 ChatGPT 时,我们讨论的是大模型与大数据创新,强悍的机器学习能力建立于此。整体来看,ChatGPT 同亚马逊云科技,在迈向未来探索之路殊途同归,创新落点都是 AI 技术、机器学习、云技术的体系化深入探索。当技术真正作用于人、真正地赋能千行百业一线场景,产生高质量、高效能后,我们所能够见到的,便能瞭望到崭新的科技边界。