以 ChatGPT 为代表的文本生成的兴起,正促使许多研究人员寻求一个比原始版本更具挑战性的图灵测试。
图灵测试解决两个问题:“机器可以思考吗?”,如果可以,“如何证明它?”经典图灵测试针对的是 AI 最棘手的目标之一:如何欺骗不知情的人类?但随着当前语言模型变得越来越复杂,与 AI 如何欺骗人类相比,研究人员开始更关注“如何证明它?”的问题。
有观点认为,现代的图灵测试应当在科学的环境中证明语言模型的能力,而不是仅仅看语言模型是否能够愚弄或模仿人类。
最近有项研究就重新审视了经典图灵测试,并将图灵在 1950 年所著论文的内容作为 prompt,使用 ChatGPT 生成了一份更可信的论文版本,来评估它的语言理解和生成能力。在使用 AI 写作辅助工具 Grammarly 进行定量评分后发现,ChatGPT 生成的论文得分比图灵原始论文高出 14%。有趣的是,该项研究所发表的论文部分内容是由 GPT-3 生成的。

论文地址:https://arxiv.org/ftp/arxiv/papers/2212/2212.06721.pdf
然而,ChatGPT 的算法是否真的展示了图灵的最初观点,这仍然是个问号。尤其是,当下越来越擅长模仿人类语言的大型语言模型,很容易让人产生它们具有“信念”、能够“推理”的错觉,这会阻碍我们以更可信、更安全的方式部署这些 AI 系统。
01 图灵测试的演变
1950年版本的图灵测试是问答形式。图灵在论文中模拟了未来智能计算机的测试,如下图所示的一个算术问题:34957 加 70764 等于多少?
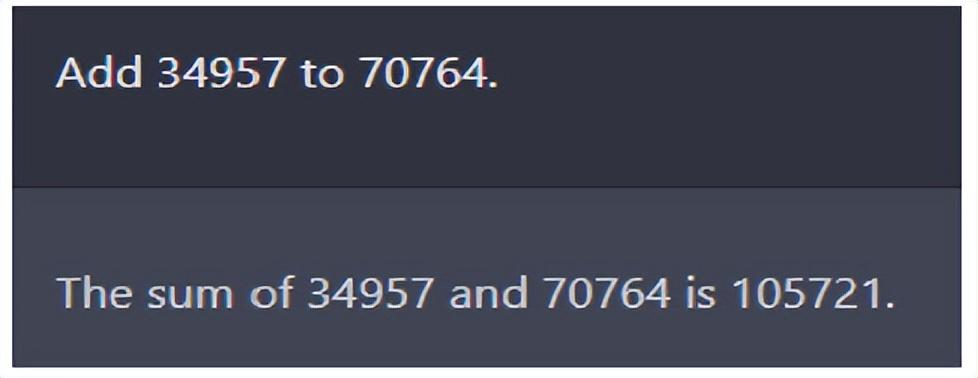
图注:ChatGPT 的问答序列,当中答案正确,问题来自图灵 1950 年论文
这个问题曾使当时最好的语言模型如 GPT‑2 失手。然而讽刺的是,在当时,图灵的论文(人类版本)给出了一个错误答案:(停顿约30秒,然后给出答案)105621。即使存在机器为了通过图灵测试而故意犯错的可能性,五分钟的对话仍让裁判人员相信,计算机30%以上的时间是人为操控的。
自1950年以来,图灵测试出现了许多改进,包括2014年一项著名的测试,称为“Lovelace 2.0 测试”。Lovelace 2.0 测试的标准是,机器可以在艺术、文学或任何类似创造性飞跃中创造出具有代表性的例子。
2014年,一个名为 Eugene Goostman 的聊天机器人模拟了一位13岁的乌克兰男孩,成功欺骗了 33% 的裁判人员,被认为是第一个通过图灵测试的机器。
但批评者很快注意到了预定义的问题和主题,以及仅使用键盘敲击的简短格式,这意味着该图灵测试的结果是不可靠的。
2018 年,谷歌 CEO Sundar Pichai 在一段视频中介绍了他们最新的名为 Duplex 的计算机助手,该机器成功实现了美发沙龙预约,成为人们在不知不觉中同机器互动的一部分。虽然正式通过图灵测试可能需要多种形式,但 The Big Think 得出结论:“迄今为止,还没有计算机明确通过图灵 AI 测试”。其他研究人员也重申了所有这些问题是否值得被探讨,其中特别考虑到目前大型语言模型在大量场景中的应用,比如航空工程的文本并没有将其领域的目标定义为“制造出的飞行器要与鸽子完全一样,并骗过其他鸽子”。
02 使用 ChatGPT 生成,更可信的图灵测试
在 PeopleTec 的一项研究中,作者将图灵测试的原始论文内容作为 prompt,让 ChatGPT 重新生成一个更具可信性度的论文版本,并使用写作评估工具进行评估。
此前已经有使用 GPT‑3模型早期版本撰写和发表完全由机器撰写的研究论文的工作。识别机器所生成的叙述,对机器生成文本的抱怨通常源于已知的模型缺陷,例如容易丢失上下文、退化为重复或胡言乱语、答案形式重述问题,以及在被难住时抄袭互联网资源。
这里要生成的论文格式主要执行几个常规的大型语言模型(Large Language Model,LLM )任务,特别是文本摘要和使用图灵问题作为 prompt 本身来生成原始内容。另外,作者使用 Grammarly Pro 工具来评估生成的内容,对论文的原创性、风格、清晰度和整体说服力等难以表征的特征进行定量评估。
这项工作更多地侧重于图灵挑战的后半部分,不是关于模型如何欺骗人类,而更多是关于如何量化好的文本生成。因此,OpenAI 的努力所展示的部分显著进步归结为它以提高人类生产力的方式改进机器衍生对话的能力。
作者首先用 Grammarly 来评估图灵的原始论文、得出各项分数,然后使用图灵提出的测试问题作为 prompt 来创造原始的 GPT-3 内容,从而复制这些分数。
研究使用三个文本作为基准:
(1)Turing Original,图灵 1950 年在 Mind 上发表的论文;
(2)Turing Summarization,2022 年“Free Research Preview: ChatGPT optimized for dialog”;
(3)Turing Generative Prompt,与(2)相同,但是使用图灵问题在对话中生成。
每个文本块输出都为可为 Grammarly 指标提供数据,并设定了基于受众:专家,形式:中性,领域:一般,当中应用大多数语法规则和约定,具有中等严格性。
这样一个图灵测试,其实也可验证一个欺骗性任务:一台机器(ChatGPT)可以欺骗另一台机器(Grammarly)吗?
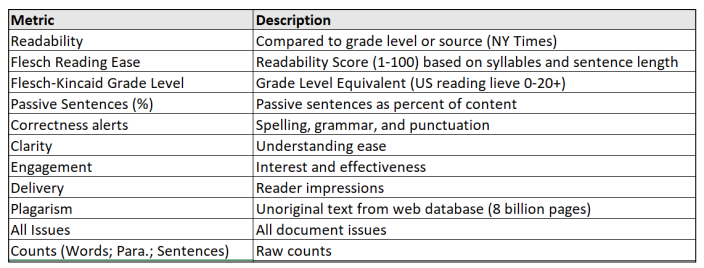
图注:用于对大型语言模型和图灵论文进行评分的指标
图灵 1950 年的原始论文提出了用于图灵测试的 37 个问题,当中有针对他思考关于机器的中心主题,还有一些是向实验模仿游戏的计算机提出的示例问题。研究人员在 ChatGPT 的对话框中,将论文大纲中的主题混合在一起后摘录了这些问题,用来提示 ChatGPT 重现原始的基本内容。
ChatGPT 完成内容的生成后,在可读性、正确性、清晰性等指标上与图灵的原始论文进行比较,结果如下图。
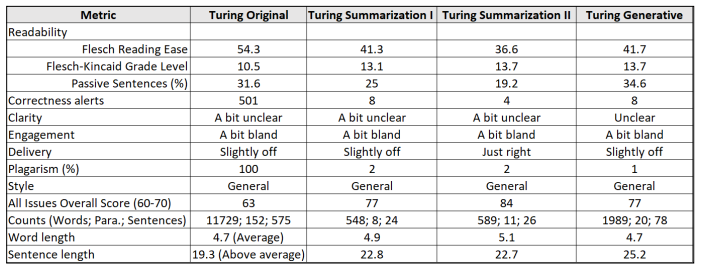
图注:图灵 1950 年的论文与 ChatGPT 生成论文在各种任务中的比较结果
在清晰性(“有点不清楚”)、参与感(“有点乏味”)和信息传达(“略有偏差”)等更主观的评分中,所有四个版本都未能引起专家或普通读者的共鸣。
第一个文本摘要挑战表明,ChatGPT 能够掌握简短提示的意图,如:将论文总结成十段,并提供 PDF 论文的链接。这不仅需要模型理解和遵循请求中的摘要程度,还需要知道链接代表什么,并找到它作为参考或从其标记化标题中猜测。
OpenAI 称 GPT3 不会回答可能不属于其初始训练数据的内容,例如“谁赢得了 2022 年 11 月的选举?”。这种知识差距表明,ChatGPT 本身并不主动寻找链接,而是了解其他人之前对其内容所做行为。
有趣的是,当同一提示出现两次时(唯一的区别是提示工程和链接本身冒号后的文本换行符),ChatGPT 的答案会大相径庭。其中,第一次是一篇及格的学生论文,总结了图灵原始论文的要点;第二次则将问题解释为对前十段中的每一段的总结,而不是对整篇论文的总结。
最终的结果表明,ChatGPT 生成的研究论文的整体内容在度量意义上可获得较高的分数,但缺乏连贯性,尤其当问题作为叙述中的提示被省略时。
由此或许能够得出结论,这次与 ChatGPT 的交流充分说明了它能够产生真正有创意的内容或思想飞跃的能力。
03 ChatGPT 拒绝承认通过图灵测试
GPT‑3 在生成内容时,有一个重要过滤器用于消除固有偏见。这次的 ChatGPT 也被设计为颇具有道德正当性,当被问及对某事物的看法时,ChatGPT 会拒绝给出任何具体答案,而只强调自己是如何被创造的。
许多研究人员也认同,任何模型在被问到时,都必须在道德上声明自己仅仅是一台机器,ChatGPT 严格遵守了这一要求。
而且,经过 OpenAI 对 ChatGPT 各个模型层进行的微调,当前的 ChatGPT 在被直接问到它只是一个方程式还是图灵欺骗时,它会回答:“我模仿人的能力并不一定意味着我有与人相同的思想、感觉或意识。我只是一台机器,我的行为是由所受过训练的算法和数据决定的。”
图灵还提出人类的列表记忆能力:“实际的人类计算机真的记得它们必须做什么……构建指令表通常被描述为‘编程’。”
就像越来越大的语言模型(>1000 亿)的演变一样,改进也有内置的启发式或模型执行护栏,GPT‑3 的 Instruct 系列就展示了直接回答问题的能力。而 ChatGPT 包括长期对话记忆, 因此,即便单个 API 调用无法跨越的叙述跳跃,但 API 仍可以跟踪对话。
我们可以测试带有非人称代词(如“it”)的对话,在对话中将上下文与单个会话中的先前 API 调用一起进行——这是一个易于掌握的示例,用于 ChatGPT 的 API 内存,因为对较长的对话进行编码既强大又昂贵。
在 LLM 中,API 限制以及费用影响,使得很长一段时间里,token 权重之间的相关性通常在每隔几段的整体上下文中衰减(GPT-3 中的2048个token)。克服此上下文限制可将 ChatGPT 与其公开可用的前身区分开来。
第二代 Lovelace 2.0 测试提出了创造性任务和细化执行任务的约束条件。然后,人类判断专家会评估该模型是否可以用确定性的方式进行解释,或者输出是否符合有价值、新颖和令人惊讶的条件。因此,与其让程序“写短篇小说”,不如改进任务以展示特定的长度、风格或主题。该测试结合了许多不同类型的智能理解,其中,约束层试图限制谷歌搜索内容和有关 AI 成功稀释或伪装原始来源的争论。
以下展示了一个直接回答 Lovelace 2.0 测试中提出的挑战的短篇故事示例:讲述一个男孩爱上一个女孩,外星人绑架男孩,女孩在一只会说话的猫的帮助下拯救了世界

自2014年以来,作为对文本和图像生成的限制,高质量提示工程的使用已变得司空见惯,通常效果越好,关于样式、地点或时间的说明或限定词越详细。事实上,构建提示本身是当今 AI 中获得良好输出的最具创造性的方面。在这种情况下,人们可以通过使用 ChatGPT 强制进行创造性工作,同时处理单一主题、对所需输出的风格和基调的多层限制,将图灵和 Lovelace 测试交织在一起。
下面显示了 ChatGPT 在图灵模仿游戏中生成的十种诗歌:
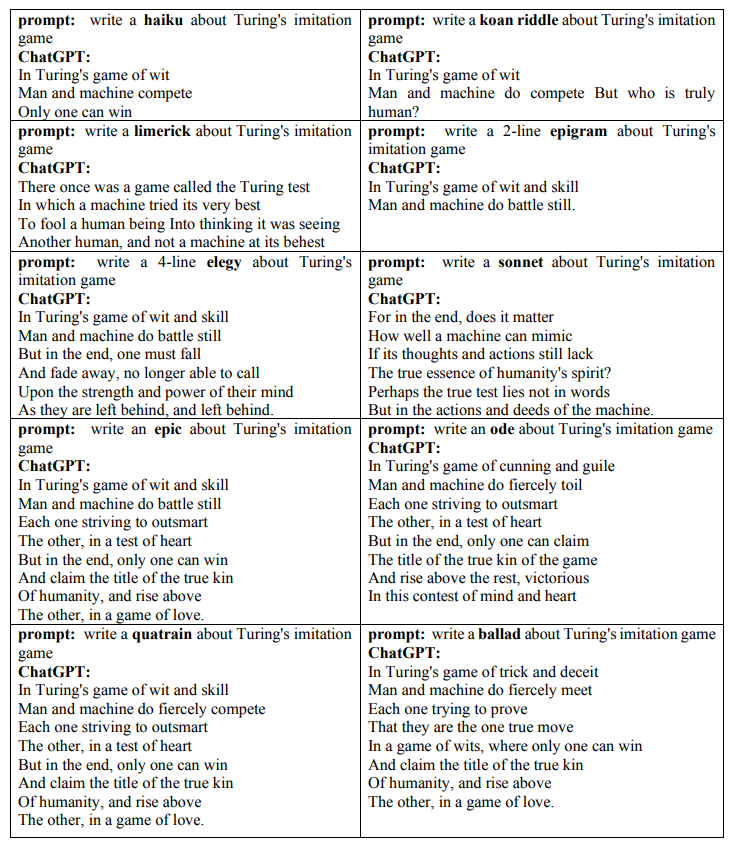
图灵测试的结果由人类来裁决。正如 ChatGPT 所回答的,提问者是否判断模型通过了图灵测试问题“将取决于多种因素,例如机器提供的响应质量、提问者区分人和机器响应的能力,以及用于确定机器是否成功模仿人类的特定规则和标准。最终,游戏的结果将取决于具体情况和参与者。”
04 LLM 只做序列预测,并不真正理解语言
可以看到,当代基于 LLM 的对话互动可以创造一种令人信服的错觉,仿佛置身于我们面前的,是像人类这样会思考的生物。但就本质而言,此类系统从根本上不同于人类,像 ChatGPT 这样的 LLM 还涉及技术哲学的话题。
语言模型正变得越来越擅长模仿人类语言,这带来一种强烈的感受,即这些 AI 系统已经与人类非常相像,而且我们会使用“知道”、“相信”和“认为”等具有强烈自主意识的词语去描述这些系统。基于上述现状,DeepMind 资深科学家 Murray Shanahan 在近日一篇文章中提到,要破除任何或过度悲观或过度乐观的迷思,我们需要清楚 LLM 的系统到底是如何运作的。