12月5日,OpenAI首席执行官Sam Altman发推表示,自ChatGPT发布后,5天内用户数量超过了100万。这在人工智能史上是个里程碑的数字,GPT-3达到该成绩花了近两年时间,DALL-E则是两个多月。

中文互联网的网友们,同样能在媒体密集且花样百出的报道中感受到由ChatGPT带来的这股AI浪潮,而这,离AI生成图像带来的冲击只有三个月。
其席卷之广、讨论之热烈较AI绘画有过之而无不及。

它被称之为最好的聊天机器人,能够快速响应人类的提问,生成有意义的回复,其优势在于能够记住同一对话的上下文,承认自身错误、质疑不正确的前提、修正自己的答案,并拒绝一些不正当的请求。
有人赞叹人工智能技术的发展,并试验其在各个领域的可行性,如取代搜索引擎,如撰写工作报告、策划方案等文档,甚至是学术论文,如翻译文本,十几种语言的相互转译都不在话下,如调试代码甚至是开发游戏……
有人试图从中找到一些新的乐子,如屡试不爽的“图灵测试”,如将AI调教成某种人格的角色,如跨过防线,诱导AI说出“禁忌”之语。
ChatGPT的热度是一个基于媒体曝光与公众参与的事件,还是一个真正的AI变革?之于游戏,它又可能产生何种影响?
ChatGPT的“社会化”
在真正领略ChatGPT之前,个人并未对这一新兴的科技产物感到好奇,毕竟聊天机器人既非新鲜事物,网友所鼓吹的“干了搜索引擎所能干的事”也不稀奇,比ChatGPT更早发布的Character.AI就有相近的出色表现:
Character.AI认为它生成的回答会更加个性化,角色扮演意味更强
至于ChatGPT的代码调试或自动生成代码功能,于年初发布的GitHub Copilot同样能做到类似的事情,前些日子它还因为版权问题被部分程序员告上了联邦法院。
GitHub Copilot能够根据上文推测后面的代码,或者根据用户输入的文字提示自行生成代码
如果要说这些AI工具有什么联系的话,那就是。
据维基百科解释,GTP-3是一个自回归语言模型,目的是为了使用深度学习生成人类可以理解的自然语言。它由Open AI训练与开发,基于谷歌开发的变换语言模型(Transformer)设计。
ChatGPT便是基于GPT-3.5架构的大型语言模型。有关于ChatGPT的运作原理与训练方法,近些天来已有专业人士进行过详细剖析,在此仅简单整理一些要点(门外汉翻阅大量资料后整理出的理解思路,仅供参考,如有错误,敬请指正):
1.GPT
全称为Generative Pre-trained Transformer,生成型预训练变换模型,是自然语言处理领域(NLP)的一种语言模型。NLP为人工智能领域的一个重要研究方向,旨在让人能够用自然语言(如汉语)跟计算机通信。
NLP可用深度学习的方法来处理,常见的方式是输入大量语料,构建一个能够在给定部分序列的情况下预测下一个符号的模型,形象的描述就是让AI做填空or文字接龙。
2017年谷歌研究出Transformer模型,不仅提高了提取数据共性特征的成功率,而且它可以进行无监督学习,有效解决人工标注数据耗时长、成本高、效率低的问题。
GPT的框架包括Transformer,其训练过程大致分为两个阶段,先利用Transformer对大量数据进行无监督学习,然后根据具体任务对参数进行微调,目的是为了研制出一种通用的人工智能。在NLP的具体任务中,GPT的文本生成能力表现尤为突出。
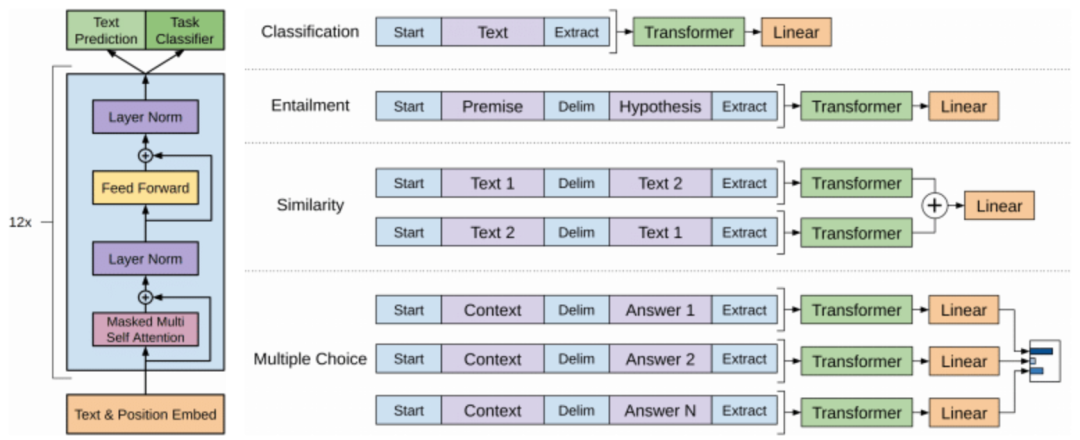
2.GPT3与GPT3.5
GPT-3(2020)拥有1750亿个参数,是有史以来参数最多的神经网络模型,是GPT-2的116倍,是GPT-1(2018)的1496倍。“数据、算力、算法”构成了AI的三大基石,从该观点看,GPT-3在NLP领域的风光无限便是大力出奇迹的有力证明,然而其代价也是巨大的,训练GPT-3估计需要上千万美元。

GTP-3.5是用2021年第四季度前的文本与代码等数据进行训练的,而ChatGPT是GTP-3.5的微调版本,其要解决的具体任务就是聊天机器人。
3. 训练方法
Open AI团队并未公开ChatGPT的论文,关于ChatGPT的解析多基于其兄弟模型Instruct GPT。
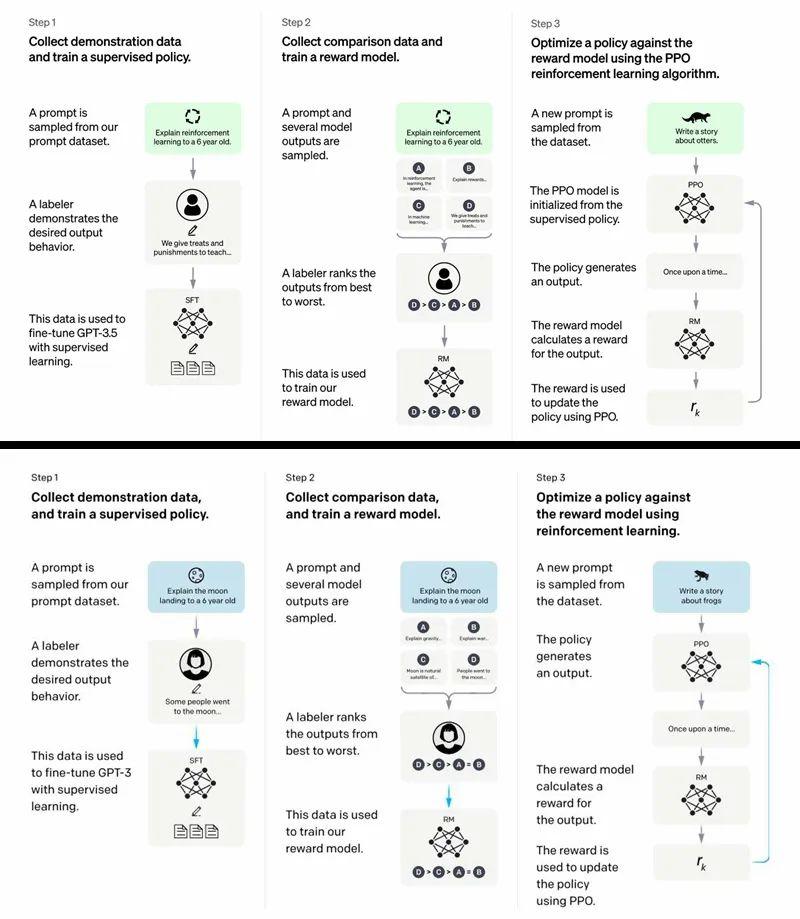
上ChatGPT,下Instruct GPT
Instruct GPT的训练主要分为三个阶段,一是由人工为GPT挑选问题并提供答案,用这些范例来训练一个生成模型,这些人工标注的大约有1万多条,目的是为了让GPT所使用的数据更偏向于人类感性趣的内容;二是用RLHF(Reinforcement Learning from Human Feedback)的方法来训练一个奖励模型,即用人类标注的方法为GPT产生的答案进行打分,从而让GPT能够预测哪种输出人类更为喜欢;三是用PPO(Proximal Policy Optimization)强化学习算法来微调第一阶段训练出来的生成模型,即将奖励模型的打分反馈给第一阶段,让模型能输出更多高分答案。
台湾大学李宏毅教授在分析Chat GPT时用了如下图例进行解释:
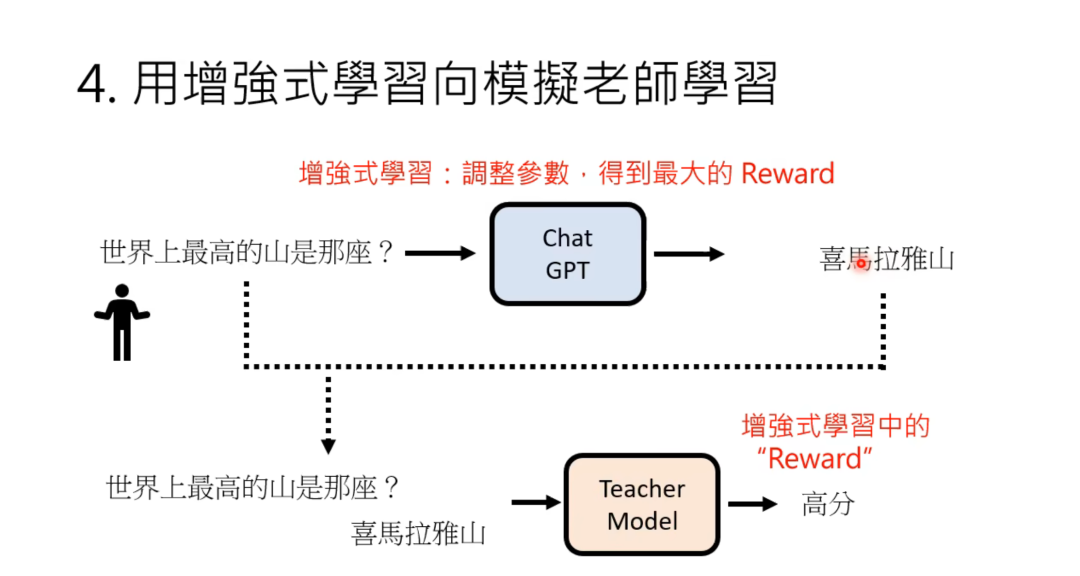
截图来源:台湾大学李宏毅教授.油管视频《ChatGPT(可能)是怎么炼成的》
在为“世界上最高的山是哪座”这一句话接龙的时候,GPT输出的回答是多样的,如“谁来告诉我”、“最深的海是哪个”,它们均为合理的表述,但不太像是人类期望的答案,因此被奖励模型判定为低分,而获得最高分的“喜马拉雅山”成了最终GPT输出的回答,在大量数据的训练与奖励模型的参数调整下,ChatGPT输出的回答越来越符合人类的认知。
李宏毅教授在评价ChatGPT的时候,用了个词——“社会化”,意指ChatGPT其实是一个社会化的过程,经由人类的引导与调整,让原本随机输出回答的人工智能变得更符合人类期待的样子,即其回答更符合提问者想要的。
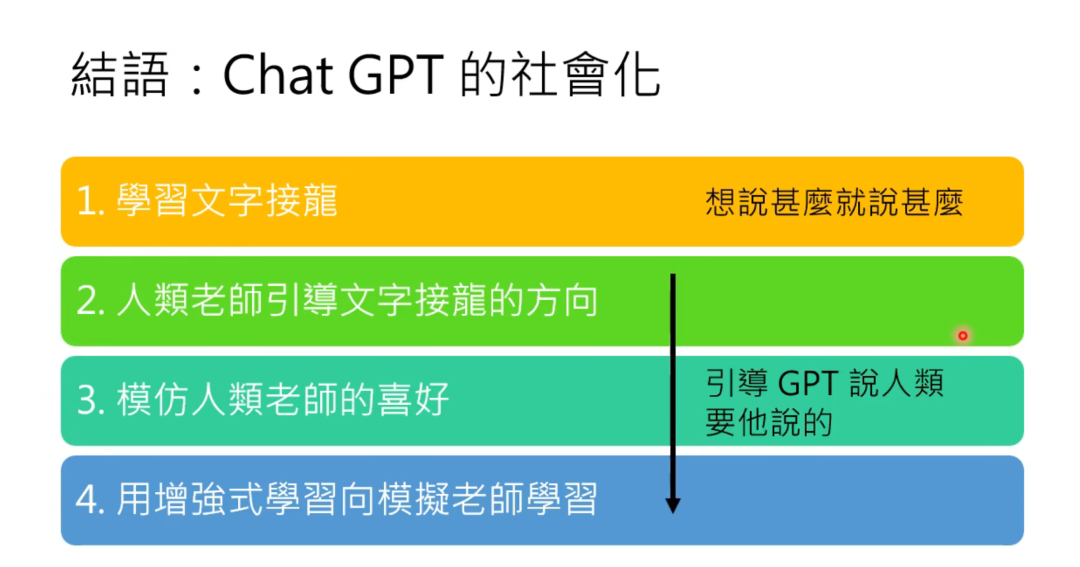
来源同上
在“社会化”之外,其实还可以加上一个词,“大众化”。
从以上的分析其实可以看出,ChatGPT其实并没有用到什么黑科技级别的算法,无论是Transformer、RLHF还是PPO,它们在学术界均是广为人知的,ChatGPT真正的领先之处在于那个花重金砸出来的大规模预训练语言模型。
ChatGPT之所以能在社会中引起如此大的反应,是因为它不再是被研究者封闭起来的项目,它向社会开放,允许公众免费使用,且因覆盖的语言种类多而造成了病毒式的扩散。
基于此,外媒theverge的编辑JAMES VINCENT用了另外一个词来形容ChatGPT引起的浪潮,“capability overhang”,意指AI的潜能,对于这些能力,研究者未曾测试过也不清楚其具体的运作。之于ChatGPT,它指的便是AI进入公共领域后所出现的未在研究者预期内的使用方式。
从官方的描述与示例来看,ChatGPT是个聊天机器人,它能够应付翻译、校对、文本分类、摘要等NLP领域的任务,可以帮助人类调试代码,会尝试着预测提问者的意图,能够在上下文语境中理解指示代词指向的对象(图灵测试经典问题),能够连续对话,并记住用户的指令或此前的“对话”。
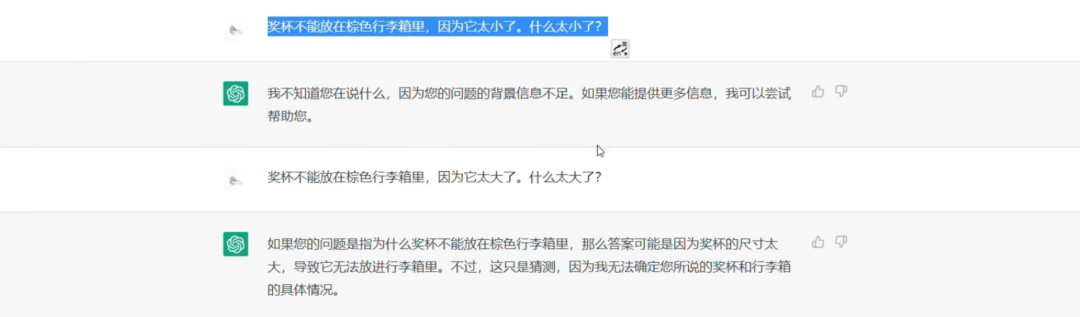
截图来源:B站用户Knight洪爵
有研究者还专门从语言模型的角度与现行标准来分析ChatGPT的能力,虽然未能挣脱语言模型长期存在的逻辑推理弱的问题,但在语义理解方面表现突出。
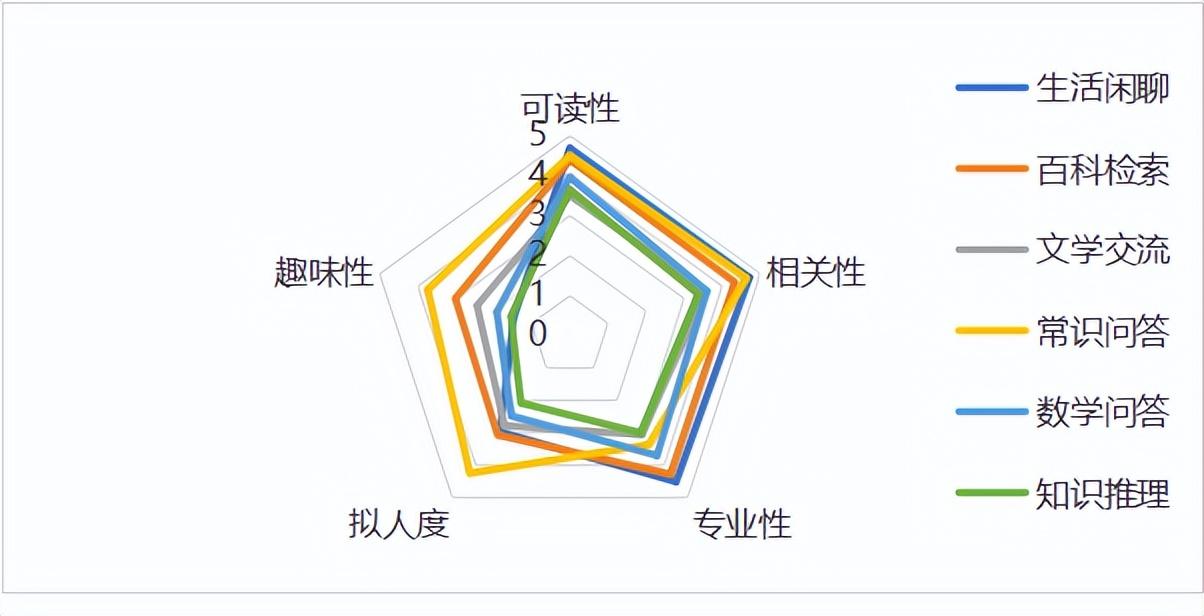
ChatGPT在多种对话任务中的主观体验评分
来源:人工智能产业发展联盟AIIA.《ChatGPT评测观察之对话能力》
但在广大网民眼中,ChatGPT绝不只是一个能跟用户沟通的聊天机器人,他们挖掘出了更多应用场景。
比如把它当成搜索引擎来使用,提供百科、常识等方面的回答;
比如把它当做文章的润色、修改助理来使用,下到日常报告、上到学术论文,它均能应付,毕竟提取摘要、润色、校对……这些算是ChatGPT的本行工作;
比如小说撰写,ChatGPT在该方面的能力远大于那些情节生成器,它能模拟某种写作风格,且在文本的相关性上有更出色的表现;
比如用ChatGPT来指导AI绘画,其生成的图片效果比用户自己瞎蒙要好得多。