ChatGPT 是 OpenAI 开发的一个基于文本生成技术的对话机器人,以其惊艳的效果迅速出圈,在这个低迷的 2023 年初,凭着一己之力重新掀起了 AI 领域的热潮。
早在上个世纪五十年代,就有学者提出了人工智能(Artificial Intelligence)的概念,其目的是希望让计算机拥有人类智能(或部分人类智能)。这个领域经过很多年的发展,依然没有突破,直到 2012 年出现了深度学习技术。深度学习主要解决了模型表示能力的瓶颈。我们面对的建模问题,比如图像理解、语言翻译、语音识别、分子 – 蛋白结合构象预测等技术,都是非常复杂的非线性问题,在深度学习出现之前,模型表示能力很弱,无法对这些复杂问题进行精确表示。而深度学习技术,可以通过模型的层次堆叠,理论上可以构建任意深度的模型,突破了模型表示能力的瓶颈,从而在语音识别、计算机视觉、自然语言理解等领域取得了突破性进展。
深度学习技术的出现标志着人工智能进入到一个新的阶段,我们姑且把 2012 年左右开始的通过深度学习驱动的人工智能浪潮叫作新一代人工智能时代(实际上在语音识别领域深度学习应用可以追溯到最早,但是鉴于后续很多深度学习的进步都来自于计算机视觉领域,所以,我们以 2012 年 AlexNet 出现作为起点)。这个时期,可以认为是深度学习驱动的新一代人工智能的第一个阶段,即标注数据驱动的深度学习模型,大幅提高了模型表示能力,从而推动人工智能技术显著提升,并且在计算机视觉和语音识别领域获得了产品和商业上的成功。这个阶段的主要局限,是非常依赖于标注数据的数量。由于模型参数变多,想要求解这么多的模型参数,需要大量的训练数据作为约束。而想获得大量的标注数据非常贵,到亿级别之后就很难再有提升,数据支撑的有效模型大小也受到限制。2012-2015 年这段时间,计算机视觉是最活跃的领域,出现了包括 ResNet 在内的各种深度网络模型。
2017 年,一个重要的基础工作 Transformer 出现了。2019 年,在一直未能有重大突破的自然语言处理(NLP)领域,一个叫作 BERT 的工作脱颖而出,在十几个不同的自然语言处理领域(NLP)任务中都取得了最好的结果,这些任务之间的差别很大,所以 BERT 工作发表后,马上引起了整个领域的关注。BERT 采用了一个叫作自监督预训练的思路,无需标注数据仅利用文本语料本身存在的约束就可以训练模型(比如某句话的某个位置只能用某些限定的词),这样互联网上存在的优质语料不需要进行人工标定就可以用来做训练,从而一下子使得可用训练数据的数量有了巨大的提高,再配合上大模型,使得 BERT 模型的效果远远超过过去的模型,并且在不同任务间具有很好的通用性,成为 NLP 领域里程碑工作之一。
其实在 BERT 出现之前的 2018 年,还有个工作叫作 GPT(即 GPT1.0),更早利用了自监督预训练的思路来做文本生成,即输入前面的文本,模型预测输出后面的文本,领域里面的优质语料无需标注就可以做训练。BERT 和 GPT 都是在 Transformer 基础上发展而来的,而 Transformer 也逐渐发展成为 AI 领域的通用模型。GPT1.0 的效果并不惊艳。在 BERT 出现后不久,GPT 很快发布了 GPT2.0,模型大小和训练数据量都有大幅提升,作为通用模型(即不用下游任务做训练,直接测试结果)在大多数任务上结果好于现有模型。但由于 BERT 模型在特征表示上比 GPT2.0 模型更有优势,也更容易训练,所以这个阶段领域里最受关注的工作还是 BERT。但 2020 年 7 月,GPT3.0 横空出世,以 1700 亿参数惊艳四座,更重要的是,在效果上,GPT3.0 作为一个通用语言模型,只需向它提供一段简单描述,说明想生成的内容,就可以在无需重新训练的情况下,根据提示,生成可执行代码,生成网页或图标,完成一篇文章或新闻,还可以编写诗歌和音乐。GPT3.0 出现后,受到了行业的广泛关注,很多开发者基于 GPT3.0 做了很多好玩的应用。GPT3.0 成为最好也最受关注的文本生成模型。
在自监督预训练技术出现之后,我们可以认为新一代人工智能发展到了第二个阶段,即自监督预训练技术使得可用训练数据有了几个数量级的提升,在训练数据大幅提升的支撑下,模型大小也有了数个数量级的提升(有效模型达到了千亿规模),而在模型效果上,这些模型变得不再依赖于下游任务领域数据的再训练,所以,领域进入到基于自监督预训练的通用大模型时代。
之后,GPT3.0 与领域其他工作一起引发了一波模型大小的军备竞赛,但鲜有真正有突破的技术出现。大家意识到仅仅增加模型大小,并不能根本上解决问题。就在大家期待 GPT4.0 等后续工作出现的时候,整整两年过去,GPT 一直没有更新。这段时间内,人工智能领域最活跃的工作主要集中在两个方面,多模态统一模型和内容生成。多模态统一模型,希望构建多模态或跨模态统一模型,尝试将文本、图像、语音等不同模态数据统一表示在一个模型中,其中包括最早的跨模态表示模型 CLIP,和后续的一系列多模态统一表示模型。而内容生成领域,一方面在技术层面,出现了扩散模型(Diffusion Model)这样的基础模型,Diffusion Model 及一系列变种模型的发展,使得人工智能内容生成(AI Generated Content,即 AIGC)领域变得非常热,从图像生成领域扩展到自然语言处理和生命科学领域;另一方面在应用层面,基于文本生成图像领域取得了很多实质进展,其中最有代表性的工作 DALLE2,模型能够按照输入的文本描述输出看起来很真实的图像,即使在文本描述超越了现实的情况下,依然可以生成看似合理符合文本描述的图像,如下图所示。DALLE2 等一系列工作的成功,一方面归功于大量的文本 – 图像对应关系数据(大约有数亿对),建模了文本和图像语义之间的对应关系,另外一方面归功于扩散模型克服了 GAN、VAE 等模型难训练、生成效果细节保留不够等缺陷。图像生成效果的惊艳,甚至让很多人相信 AI 已经可以创造内容了。

图 DALLE2 生成效果
时间来到了 2022 年 11 月底,OpenAI 发布了 ChatGPT。ChatGPT 发布后,大家发现这个聊天机器人很不一般,经常给出令人惊艳的回答。对话机器人领域曾出现过很多个对话机器人,比如苹果的 Siri,微软的小冰小娜等,这些通用对话系统的体验都不是非常理想,大家拿来调戏一下就扔到了一边。而智能音箱等产品中使用的指令执行式问答机器人,系统框架是基于规则驱动的对话管理系统,存在大量的手工规则,使得这些系统一方面无法扩展到通用领域,只能进行简单程式化的回答,另一方面,无法处理多轮对话的环境语义信息(Context)。从技术层面看,ChatGPT 和原来主流的对话系统完全不同,整个系统基于一个深度生成大模型,对于给定的输入,经过深度模型的处理,直接输出抽象总结性的回答。而在产品体验上,ChatGPT 也远远超越了过去的聊天系统。作为一个通用聊天机器人,它几乎可以回答任何领域的问题,而且准确率已经达到人类愿意持续使用的要求,在多轮对话的场景下依然保持非常好的体验。
当然,ChatGPT 并不完美,作为一个深度学习模型,ChatGPT 存在无法百分之百精准的缺陷,对于一些需要精确回答的问题(比如数学计算、逻辑推理或人名等),会出现一些可感知的明显错误。后面又出现了一些改进工作,比如有些工作会提供信息的参考网页链接,而在 Facebook 最新的工作 ToolFormer 中,则尝试在生成模型中,将特定任务交给特定 API 去计算,不走通用模型,这有望克服模型无法百分之百精准的问题。如果这条路走通,深度生成模型有望成为 AGI 的核心框架,用插件方式集成其他技能 API,想想就很激动人心。
商业上,ChatGPT 一方面引发了对于 Google 等搜索引擎挑战的畅想,另一方面,大家看到了各种自然语言理解有关的垂直产品应用机会。无疑,ChatGPT 在自然语言理解领域正掀起一次可能媲美搜索推荐的新商业机会。
ChatGPT 为什么能有这样惊艳的效果?其中一个核心原因是 ChatGPT 基于生成大模型 GPT3.5 构建,这应该是当前自然语言理解领域文本生成最好的模型(GPT3.5 比 GPT3.0 使用了更多的数据和更大的模型,具有更好的效果)。
第二个核心原因则是基于人类反馈的强化学习技术,即 Reinforcement Learning from Human Feedback(简写作 RLHF)。由于 OpenAI 并没有发表 ChatGPT 的论文,也没有代码公开,大家一般认为其与之前的一篇文章 InstructGPT(
https://arxiv.org/pdf/2203.02155.pdf)中批露的技术最为相近。如下图所示,按照 InstructGPT 中的描述,第一步,先收集用户对于同一问题不同答案的偏好数据;第二步,利用这个偏好数据重新训练 GPT 模型,这一步是基于监督信息的精调;第三步,根据用户对于不同答案的偏好,训练一个打分函数,对于 ChatGPT 的答案会给出分数,这个分数会体现出用户对于不同答案的偏好;第四步,用这个打分函数作为强化学习的反馈(Reward)训练强化学习模型,使得 ChatGPT 最终输出的答案更偏向于用户喜欢的答案。通过上述过程,ChatGPT 在 GPT3.5 的基础上,针对用户输入,输出对用户更友好的回答。
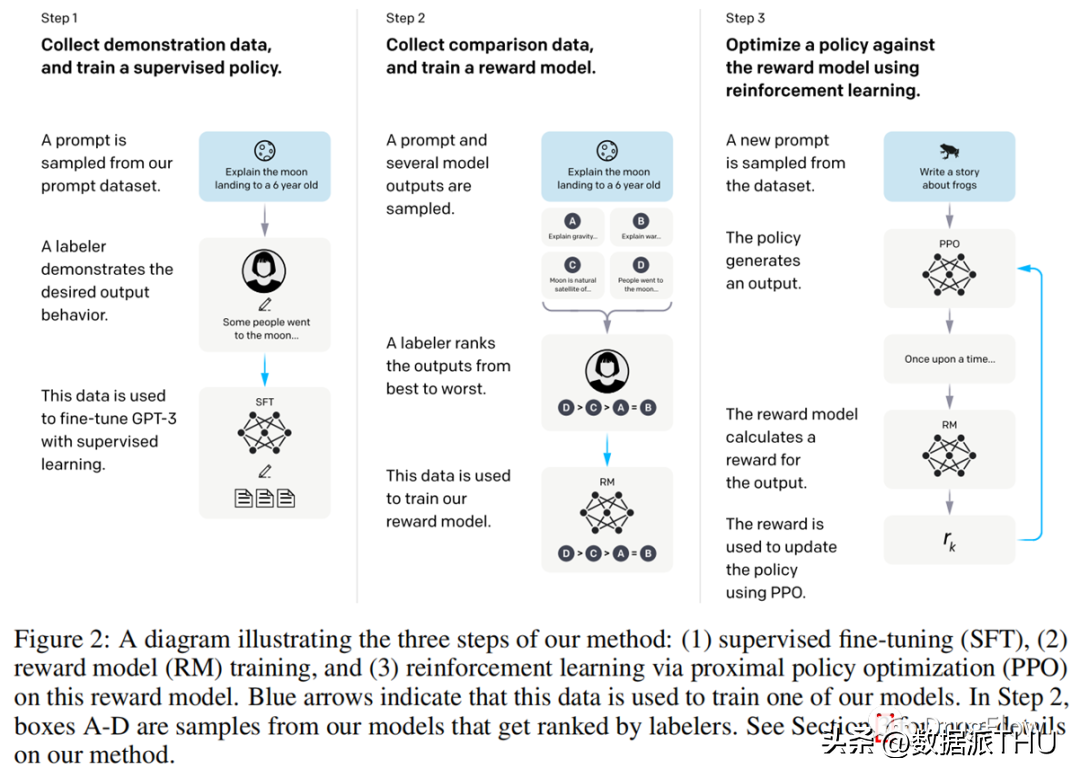
ChatGPT 第一阶段训练 GPT 生成模型使用的训练数据非常多,大约在几十 TB,训练一次模型需要花费千万美元,而第二个阶段,基于强化学习的少量优质数据反馈则只需要数万条优质数据。我们可以看到,ChatGPT 技术,是在自监督预训练大模型基础上结合基于人类反馈的强化学习技术,取得了非常显著的进展。这种新的范式,有可能成为第三阶段人工智能的核心驱动技术,即首先基于自监督预训练的大模型,再结合基于少量优质数据反馈的强化学习技术,形成模型和数据的闭环反馈,获得进一步的技术突破。
关于 ChatGPT,我们的观点如下:
(1)ChatGPT 确实是这个时代最伟大的工作之一,让我们看到了基于自监督预训练的生成大模型与基于少量优质数据强化学习反馈策略结果后 AI 的惊艳效果,某种意义上改变了我们的认知。
(2)ChatGPT 相关技术具有非常大的商业价值,使得搜索引擎在内的很多产品都面临被重构或者颠覆的机会,无疑会带来很多新的商业机会,整个 NLP 领域都会受益。
(3)基于自监督预训练的生成大模型与基于少量优质数据强化学习反馈策略的学习范式,有望成为未来推动各个领域前进的动力,除 NLP 领域外,有望在生命科学、机器人、自动驾驶等各个领域引发新一轮人工智能热潮。
(4)ChatGPT 并不能证明人工智能已经有了人类心智,ChatGPT 表现出来的一些创造性和心智,是因为自然语言理解语料中包含了语义、逻辑,基于自然语言语料训练出来的生成模型,统计意义上学习到了这些对应关系,看起来似乎有了智能,但并不是真的有人类心智。ChatGPT 很棒,但说他智力等于几岁小朋友的说法,都不够严谨。因为从根本上讲,人学习新知识、进行逻辑推理、想象、运动反馈这些能力,目前 AI 还没有具备。过度炒作 ChatGPT 的智能和能力,会劣币驱逐良币,损害整个行业。
(5)在这个领域,中国的技术还有差距,过去两年,我们还没有看到真正复制出 GPT3.0 效果的文本生成模型,而没有 GPT3.0 和 3.5,就不会有 ChatGPT。GPT3、GPT3.5 和 ChatGPT 等工作都没有开源,甚至 API 都对中国做了封锁,这都是复制工作实际面临的困难。说得悲观一点,大部分想复制 ChatGPT 效果的团队,都不会成功。
(6)ChatGPT 并不是一两个研究人员做出的算法突破,而是在先进理念指导下,非常复杂的算法工程体系创造出来的成果,需要在团队和组织上匹配(类比 OpenAI 和 DeepMind)。纯研究型的团队恐怕不能成功,对深度学习理解不够、太工程化的团队也不会成功。这只团队需要:第一要有足够资源支持,可以支撑昂贵的深度学习训练和人才招聘;第二要有真正在工业界领导过工程化大模型团队的专家领导,ChatGPT 不仅有算法创新,更是工程体系创新;第三,也可能是最重要的,需要一个团结协作有统一领导且不追求论文发表的组织(松散型的组织利于算法创新,但不利于工程化算法攻坚),且配备足够多优秀的工程和算法人才。
(7)我们不仅追求做一个 ChatGPT,更要持续追求其背后的技术创新,即大力发展自监督预训练生成大模型和基于少量优质数据的强化学习反馈策略技术,这既是下一代 ChatGPT 的核心技术,也是推动人工智能领域整体进步的技术。最担心的是,由于投机追风,造成力量分散而使大量资源被浪费,或者过度宣传 ChatGPT 损害了行业。
(8) ChatGPT 还存在改进空间,也不是唯一值得关注和期待的技术。对于 AI,最常见的误区是,高估其短期表现,而低估其长期表现。这是一个 AI 成为核心推动力的伟大时代,但 AI 并不会那么快无所不能,需要我们长期努力。
这里,我们简单总结一下 2012 年以来深度学习引起的新一代人工智能浪潮里面的关键技术演进:
(1)第一个阶段,关键进展是标记数据驱动的有监督深度学习模型,大幅提高了模型表示能力,从而推动人工智能技术显著进步,这个阶段最活跃的是计算机视觉和语音识别领域,主要的局限是有标记数据比较贵,限制了可以获得的数据量,进而限制了数据能支撑的有效模型大小。
(2)第二个阶段,关键进展是自监督预训练大数据驱动的通用大模型,自监督预训练技术使得可用训练数据有了几个数量级的提升,从而支撑着模型大小也有了数个数量级的提高,成为无需依赖下游任务领域数据再训练的通用模型,这个阶段进步最大、最活跃的是自然语言理解领域;主要的局限在于需要海量数据训练,且模型非常大,训练和使用都非常昂贵,重新训练垂直场景模型也非常不方便。
(3)第三个阶段,目前虽然还不能盖棺论定,但呈现出一定趋势。未来非常重要的技术关键在于,能否在大模型的基础上,用强化学习、Prompting 等方式,仅通过少量优质数据就能显著影响大模型的输出结果。如果这个技术走通,那么无人驾驶、机器人以及生命科学等数据获取昂贵的领域将显著受益。过去,如果想改善 AI 模型存在的问题,必须采集大量的数据重新训练模型。假如,在需要线下交互的机器人领域,在预训练大模型的基础上,仅通过告知机器人真实场景中一些正确和错误的动作选择就能影响机器人的决策,那么无人驾驶和机器人领域在技术迭代上会更加高效。生命科学领域,如果仅通过少量的试验数据反馈,就能显著影响模型预测结果的话,整个生命科学领域与计算融合的革命将会来得更快一些。在这一点上,ChatGPT 是非常重要的里程碑,相信后面还会有非常多的工作出现。
让我们把目光回到我们更关注的生命科学领域。
由于 ChatGPT 带来的技术进步改善了大多数 NLP 相关领域,所以,生命科学领域内和信息查询检索抽取有关的技术和产品,会优先受益。例如,在未来有没有可能出现一个生命科学领域对话方式的垂直搜索引擎,专家可以向它询问任何问题(比如关于疾病、靶点、蛋白等有关的问题),它一方面可以给出综合趋势的判定(也许没有那么精确,但大概正确,有助于我们快速了解一个领域),另一方面可以给出关于某个话题的相关有价值资料,这无疑会显著改善专家的信息处理效率。还例如,能否构建一个 AI 医生,病人可以咨询有关疾病的知识和处理办法(限于技术的局限,AI 无法给出精确的答案,更无法代替医生),但可以给出很多信息参考和后续该做什么的建议,其体验一定会显著优于现在的搜索引擎。
生命科学领域本身还存在很多没有被解决的重要任务,比如小分子 – 蛋白结合构象和亲和力预测、蛋白 – 蛋白相互作用预测、小分子表示和性质预测、蛋白质性质预测、小分子生成、蛋白质设计、逆合成路线设计等任务。目前看这些问题还没有被完美解决,如果在这些任务上取得突破,那么药物发现甚至整个生命科学领域,都会迎来巨大变化。
基于大模型的 AIGC 领域,以及基于专家或试验反馈的 RLHF 领域,受益于 ChatGPT 的推动,一定会引来一轮新的技术进步。其中 AIGC(人工智能内容生成)技术,在过去一年中,已经在小分子生成、蛋白质设计等领域取得了不错的进展。我们预测,在不远的未来,下列任务将显著受益于 AIGC 生成技术的发展,产生技术阶跃:
(1)小分子生成和优化技术,即如何不依赖活性配体信息,而是基于蛋白口袋结构信息生成综合考虑活性、成药性、可合成性等多种条件约束的配体小分子,这部分技术将显著受益于 AIGC 领域的发展;
(2)构象预测某种意义上可以看作是生成问题,小分子和蛋白结合构象预测任务也会受益于 AIGC 相关技术的发展;
(3)蛋白质、多肽、AAV 等序列设计领域,也一定会受益于 AIGC 技术的发展。
上述 AIGC 相关任务,以及几乎所有需要试验验证反馈的任务,包括但不限于活性预测、性质预测、合成路线设计等,都将有机会受益于 RLHF 技术带来的红利。
当然也存在很多挑战。受限于可用数据数量,当前生命科学领域使用的生成模型还比较浅,主要使用的是 GNN 等浅层深度学习模型(GNN 受限于消息传递的平滑性,层数只能使用到 3 层左右),生成效果上虽然体现了很好的潜力,但依然没有 ChatGPT 那样惊艳。而基于专家或试验反馈的强化学习技术,受限于试验数据产生速度以及生成模型表示能力不够的影响,惊艳效果呈现也会需要一定的时间。但从 ChatGPT 技术演进趋势推演,如果能训练足够深、表示能力足够强的生成大模型,并且利用强化学习,基于少量优质试验数据或者专家反馈来进一步提升生成大模型的效果,我们可以预期 AIDD 领域一定会迎来一次革命。
简而言之,ChatGPT 不仅是自然语言理解领域的一项技术进步,会引发新一轮信息服务和内容生成领域的商业潮流,同时,其背后基于海量数据的深度生成技术,以及基于人类反馈的强化学习技术,是更长远的进步动力,会引起生命科学等领域的长足发展。我们会再迎来一次 AI 技术进步和产业落地的浪潮。