大模型模式,正在新一波AIGC的浪潮里被再度验证。
从AI画画的出圈,到现如今ChatGPT的火爆,面向大众的爆款产品接口背后,无不是大模型技术的突破创新。
而当这种“大力出奇迹”的技术路径价值愈发凸显,行业内外也不禁好奇:
AI绘画、ChatGPT版搜索之后,下一个大模型的爆发点会出现在何处?

遵循技术规律推测,可以预见的是,视频领域的技术革命已近在眼前:
从技术的角度来说,在大语言模型迭代进化的同时,谷歌、Meta等大厂在视频自动生成领域已有更深层的探索。
而从商业的视角来看,中信建投就在报告中指出,AIGC在文本、音频、视频、游戏等等行业中,成长空间巨大。
量子位智库也预测,AI生成视频将在5年后迎来较为广泛的规模应用。
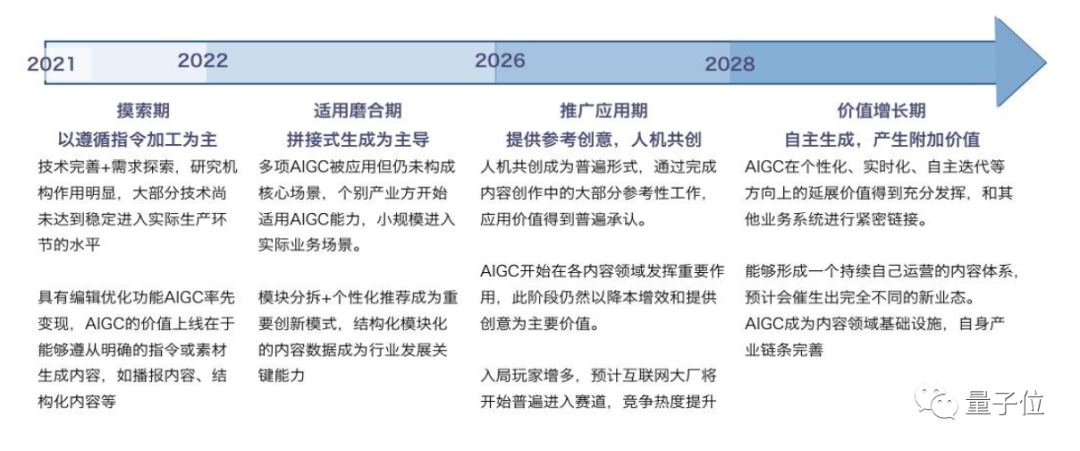
△图源:量子位智库
AIGC下一站:视频生成
不妨先展开看看相关领域的技术进展。
谷歌:Phenaki和Imagen Video
就在ChatGPT刷屏之际,谷歌AI生成的一段视频突然爆火,一时分走不少讨论度。
背后的AI模型名为Phenaki。只需提供一段提示词,这个文本转视频(Text-to-Video)模型分分钟就能生成长达两分钟的视频。
不仅时长远超早期的文生视频模型,Phenaki生成的视频还颇具故事性。
比如给它这样一段场景描述:
一只逼真的泰迪熊正在潜水;随后它慢慢浮出水面;走上沙滩;这是镜头拉远,泰迪熊行走在海滩边篝火旁。
就能得到一个这样的视频片段:

除此之外,谷歌还推出过基于扩散模型的Imagen Video。其特点是分辨率高,同时可以理解不同的艺术风格和3D结构。

Meta:Make-A-Video
在“拿嘴做视频”这方面,Meta也有所布局。
Meta的文生视频模型名为Make-A-Video,同样是文本图像生成模型的升级版,主要由三部分组成:
文本图像生成模型P
时空卷积层和注意力层
用于提高帧率的帧插值网络和两个用来提升画质的超分模型
不仅给出一句“马儿喝水”,Make-A-Video就能生成出一段“纪录片”画面来:

这个AI模型还具备将静态图像转成视频、根据前后两张图片生成一段视频,以及基于一段原视频生成新视频的能力。

百度:VidPress
国内,百度也把文心大模型的能力,运用到了智能视频合成平台VidPress中。
VidPress能够实现图文自动转视频,即把文字脚本、视频内容搜索、素材处理、音视频对齐,以及剪辑这5个步骤自动化。
其中涉及的语义分析、素材相关度打分等环节,就都是基于文心大模型训练实现的。
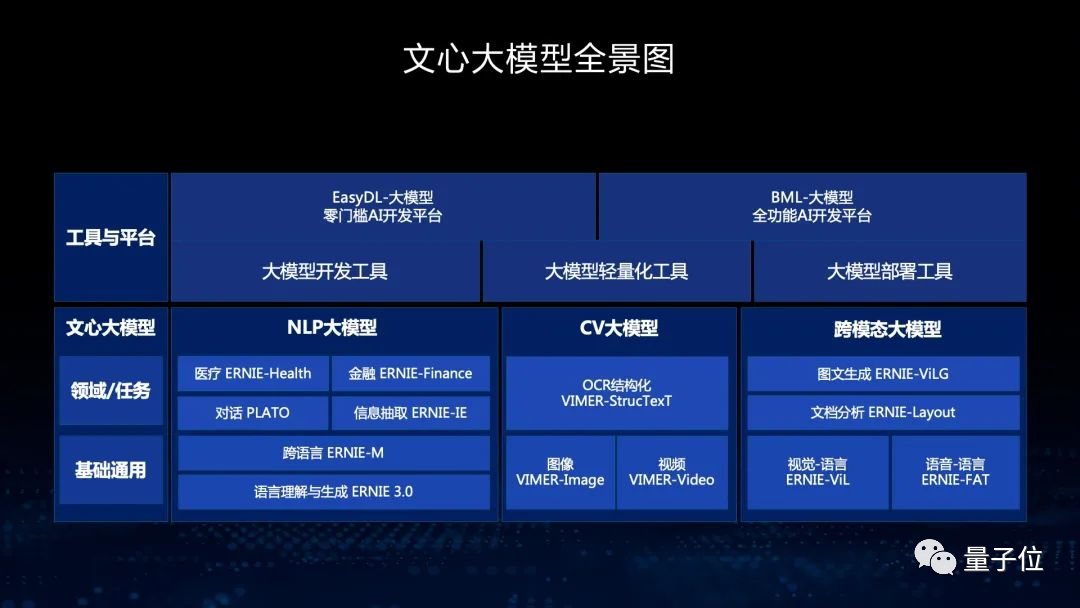
从技术的发展可以看出,在语言大模型、图像大模型之后,多模态大模型已经成为了新的趋势。视频就是其中具有代表性的一个应用领域。
而从商业化的角度来看,文化娱乐、教育、传媒等诸多领域,本身就对基于AI的可视化内容有强烈需求。
根据中信建投对各类内容未来可AI制作比例的测算,在视频成为信息主要表达载体的当下,无论是在游戏、短视频、直播,还是影视等领域,AI视频内容生成都将成为AIGC的主要关注方向。
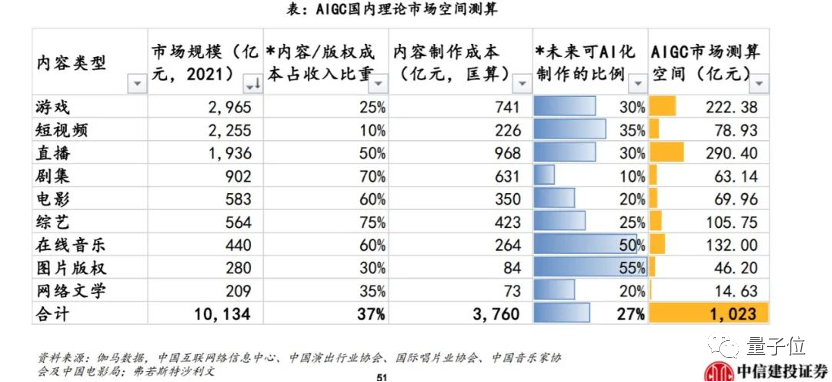
并且在2022年,DALL·E、Imagen、Stable Diffusion等多个高质量文生图大模型的“轰炸”之下,一个新的市场规律已经得到验证:
当生成质量提高到专业水平时,原本AI生成内容的商业化瓶颈,如变现困难等,将得到突破。
哪些公司是潜力股?
机会自然属于有准备的人。
比如,Image Video的核心团队就已经从谷歌出走创业。据VC爆料,首轮估值1亿美元。
而除了前文提到的已有革命性技术储备的科技巨头外,还有两类公司值得关注。
其一,是具备数据基础和应用场景的公司。
在这一方面,行业中的大公司普遍更具优势。比如国外的网飞、迪士尼。
以网飞为例,公开资料显示,在2012年时,网飞就已拥有数十亿条会员评价,每天能新增百万级别的视频播放信息,包括观众的观看时长、播放设备等等。
事实上,基于如此庞大的独家数据,网飞已经在产品中尝试用AIGC替代标准内容制作。比如影片的缩略图,就是网飞采用AI算法,从影片中抽取符合用户观影习惯和需求的画面生成的。
就在今年2月初,网飞还发布了一支AIGC动画短片《犬与少年》。其中动画场景的绘制工作,都是由AI完成的。

同样,国内短视频行业两大巨头抖音和快手的动向,也值得关注。
目前,字节跳动的视频编辑工具剪映,以及快手的云剪,都已上线图文成片、文字转视频的功能。用户只需输入几个关键词或一段文字,AI就能自动搜集素材剪辑出一段视频片段。
其二,就是在垂直细分赛道上具有技术储备的公司。
比如国内的智能视觉技术企业影谱科技,成立之初就是以人工智能视觉技术产业化为主要目标,早在2018年就发布了基于生成式AI技术的AGC智能影像生产引擎,这也是国内较早提出的生成式AI的技术框架。
影谱科技的AGC通过MCVS技术(Moviebook Motion Capture from Video System)对现有视频的关键帧进行抽取,理解、关联及预测等处理,将视频内容分割为像素及子像素维度的结构化数据,并自动完成标记,即形成了对视频中各种内容的自动化理解和标注。接下来,利用3D虚拟重建等计算机图像技术,通过视频内容自动化生产引擎MAPE(Moviebook Auto-Production Engine)生成全新的视频,该方案融合了人工智能多模态语义理解,并利用深度学习实现视频自动化加工以及视频的同步生成,创新了视频影像生产方式。
这使得AGC可在极短时间内生成一段个性化视频内容,亦可以对拍摄视频进行重构,如自动锚定关键帧,根据帧内容生成原图像中没有的、无违和感的内容,再智能化生成一段AI视觉内容。
据公开数据显示,影谱科技AI生成引擎生成一段60s视频的总成本与传统方式相比降低79.8%以上,而生产率最高可以提高百倍以上;检索一段60s视频内相似帧图像或特定图像,所需总成本与人工相比降低99.73%,而错误率降低10倍以上,目前主要应用于政府服务、企业、科教、泛娱乐、媒体、文旅等领域。

例如,在视频采集和生产阶段,可实现主体识别、跟随拍摄、画质修复、自动剪辑、视频自动生成等功能;在分发阶段实现智能审核、个性化推荐等;在用户体验方面,结合数字孪生技术综合使用,实现数字内容、数字空间、数字人的高效生产及可视化互动等功能。
目前AGC在诸多行业的应用已十分广泛,随着与行业的数字化融合不断加深,未来发挥的作用也将愈加明显。
p.s. 前文提到的网飞AIGC短片,还有小冰公司的参与。
ChatGPT之火,正在加速AIGC走向成熟
不得不说的是,尽管ChatGPT的火爆,让大模型时代的AIGC获得了空前关注,但AIGC产业,还只能说是一个“新生儿”。
根据Gartner发布的2022年新兴技术成熟度曲线,生成式AI目前还处于“技术萌芽期”,预计距离生产成熟期还有5-10年的时间。
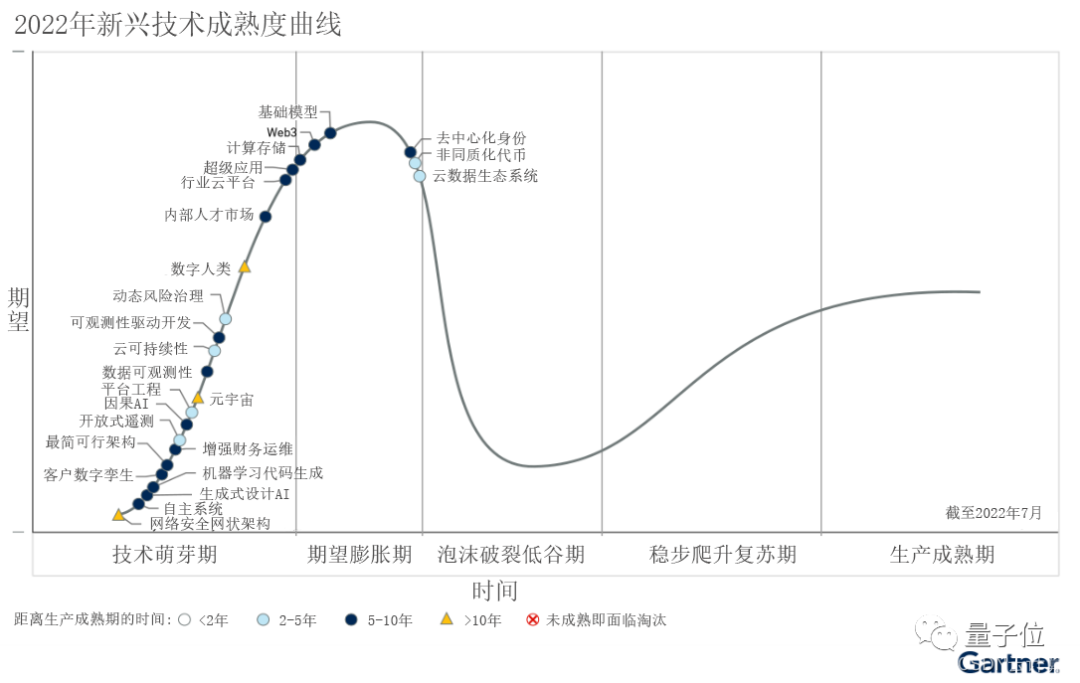
但随着大模型这样的技术底座作用愈发凸显,越来越得到重视,不可否认的是,这个新生儿成长态势正呈现出一种加速状态。
并且,经过文生图、ChatGPT的验证,AIGC在其他垂直领域中的可拓展空间已经可以预见。
量子位智库预测,2030年,AIGC市场规模有望超过万亿人民币。
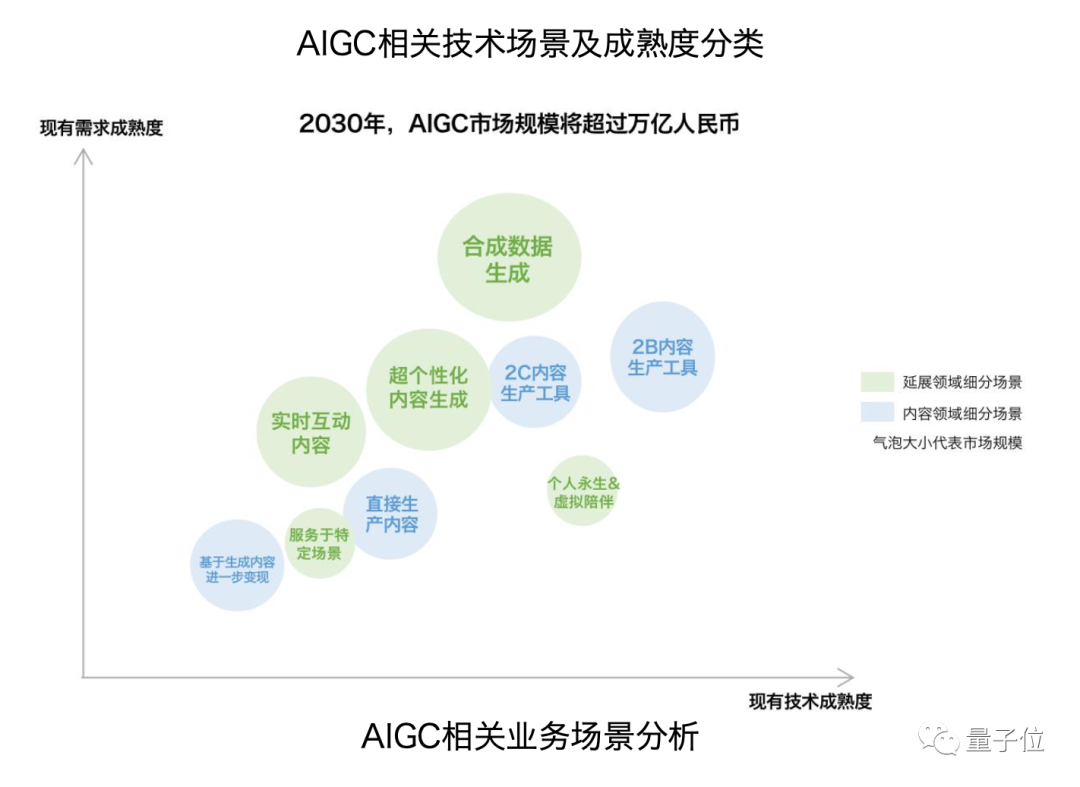
在这个过程中,如何抢占先机,将成为中国产业界亟需关注的命题。
至少,像影谱这样的垂直赛道种子选手,就已经得到国资基金的重视:具备国家社保基金、中央企业、国有银行、地方国资等出资背景。并且D轮融资13.6亿人民币,创下人工智能视觉生产领域的中国最高融资纪录。
这一回,我们能否走在世界之先?