ChatGPT的爆火引爆了AI行业,全球科技巨头争相杀入这一领域展开混战。周五,Meta也宣布推出大型语言模型LLaMA,加入到由微软、谷歌等科技巨头主导的AI“军备竞赛”中。
当地时间2月24日,Meta宣布将推出针对研究社区的“Meta人工智能大型语言模型”系统(Large Language Model Meta AI),简称“LLaMA”。
同ChatGPT、New Bing不同,LLaMA并不是一个任何人都可以与之对话的产品,也并未接入任何Meta应用。更为确切地说,该产品将是一个开源的“研究工具”。
公司CEO扎克伯格在社交媒体上表示,LLaMA旨在帮助研究人员推进研究工作,LLM(大型语言模型)在文本生成、问题回答、书面材料总结,以及自动证明数学定理、预测蛋白质结构等更复杂的方面也有很大的发展前景。


开源的“研究工具”
Meta表示,LLaMA可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者,正在接受研究人员的申请。
此外,LLaMA将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。与之截然不同的是,谷歌旗下的DeepMind和OpenAI并不公开训练代码。
该公司还表示,LLaMA作为一个基础模型被设计成多功能的,可以应用于许多不同的用例,而不是为特定任务设计的微调模型。

比GPT3.5性能更强
根据Meta官网介绍,LLaMA包含4个基础模型,参数分别为70亿、130亿、330亿和650亿。其中,LLaMA 65B 和 LLaMA 33B 在 1.4 万亿个 tokens 上训练,而最小的模型 LLaMA 7B 也经过了 1 万亿个 tokens 的训练。
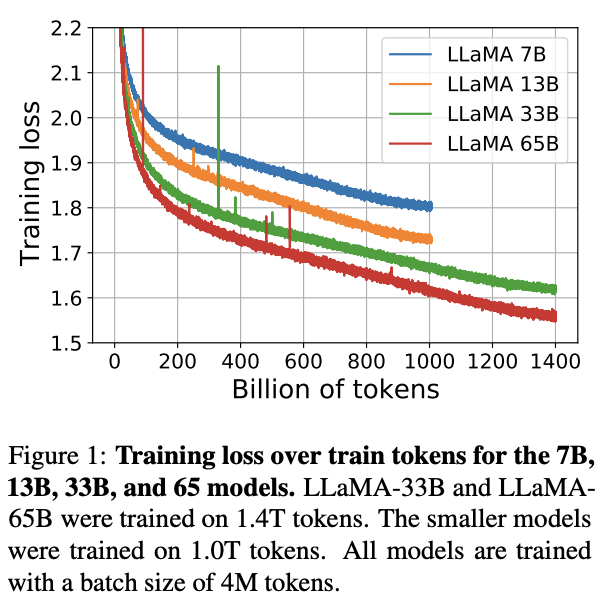
Meta表示,在大多数基准测试中,参数小的多的LLaMA-13B的性能优于GPT3.5的前身GPT3-175B,而LLaMA-65B更可与业内最佳的Chinchilla-70B和PaLM-540B竞争。值得一提的是,近期大火的ChatGPT便是由GPT3.5提供支持。
Meta 还提及,LLaMA-13B对算力的要求“低得多”,可以在单个数据中心级GPU(Nvidia Tesla V100)上运行。
扎克伯格写道:
“Meta 致力于这种开放的研究模式,我们将向 AI 研究社区提供我们的新模型。”
值得一提的是,去年5月,Meta 也曾推出过大型语言模型 OPT-175B。该项目同样也是针对研究人员的,这构成了其聊天机器人 blenterbot 新迭代的基础。后来,该公司还推出了一款名为“卡拉狄加”(Galactica) 的模型,但因经常分享偏见和不准确的信息而遭到下架。
据媒体报道,扎克伯格已将人工智能作为公司内部的首要任务,其本人也经常在财报电话会议和采访中谈论它对改进 Meta 产品的重要性。媒体分析称,虽然现在 LLaMA 没有在 Meta 产品中使用,但未来不排除使用的可能。
最近微信改版
经常有读者朋友错过推送
星标?“华尔街见闻”
及时接收新鲜推文
本文不构成个人投资建议,不代表平台观点,市场有风险,投资需谨慎,请独立判断和决策。