财联社2月25日讯(编辑 笠晨)科技部周五表示,将把人工智能作为战略性新兴产业,继续给予大力支持。券商研报指出,以ChatGPT为代表的预训练大模型加速商业化落地,将带来大量算力需求。以政府为主导的城市智能计算中心AI算力卡国产化进度较快,其中以城市数量计,华为昇腾国内市场份额约79%,处于领先且具备大模型能力。

华为昇腾芯片是华为公司发布的两款人工智能处理器,包括昇腾910和昇腾310处理器。昇腾是华为全栈全场景AI解决方案的关键部分,是华为落地全面AI战略的重要支撑。中信证券杨泽原等人在2月16日发布的研报中表示,国内千亿参数大模型如华为盘古使用超过2000块华为昇腾910以640P FLOPS的FP16算力训练超过两个多月,可见大模型训练算力耗费之巨大,算力扩容需求明确。

在 2月13日举行的北京人工智能产业创新发展大会上,北京市经济和信息化局发布《2022年北京人工智能产业发展白皮书》。据悉,截至2022年10月,北京拥有人工智能核心企业1048家,占我国人工智能企业总量的29%,位列全国第一。今年,北京将支持头部企业打造对标ChatGPT的大模型,着力构建开源框架和通用大模型的应用生态。加强人工智能算力基础设施布局,加速人工智能基础数据供给。
华为昇腾计算业务总裁张迪煊在北京人工智能产业创新发展大会上表示,截至2023年2月,昇腾AI产业生态已发展超过20家硬件合作伙伴,1000多家软件伙伴,联合推出超2000个解决方案,开发者数量突破120万人。会上,清华大学、首都经贸大学与北京昇腾人工智计算中心分别在自动驾驶大模型、金融大模型方面达成合作。

据经销商表示,近期CHATGPT大火,国内很多企业准备训练AI,近期华为昇腾AI服务器,兆瀚RA5900-A系列AI训练服务器等AI服务器询单量及预定量有爆发式增长。
兴业证券蒋佳霖等人表示,昇腾为平安城市、自动驾驶、云服务和 IT 智能、智能制造、机器人等应用场景提供了全新的解决方案,使能智慧未来。建议关注AI领域龙头公司投资机会。在AI算法、AI算力涉及的上市公司分别为科大讯飞、中科曙光;AI+汽车有布局的上市公司为中科创达、锐明技术、千方科技、四维图新;在AI+金融触及的上市公司为恒生电子、同花顺。
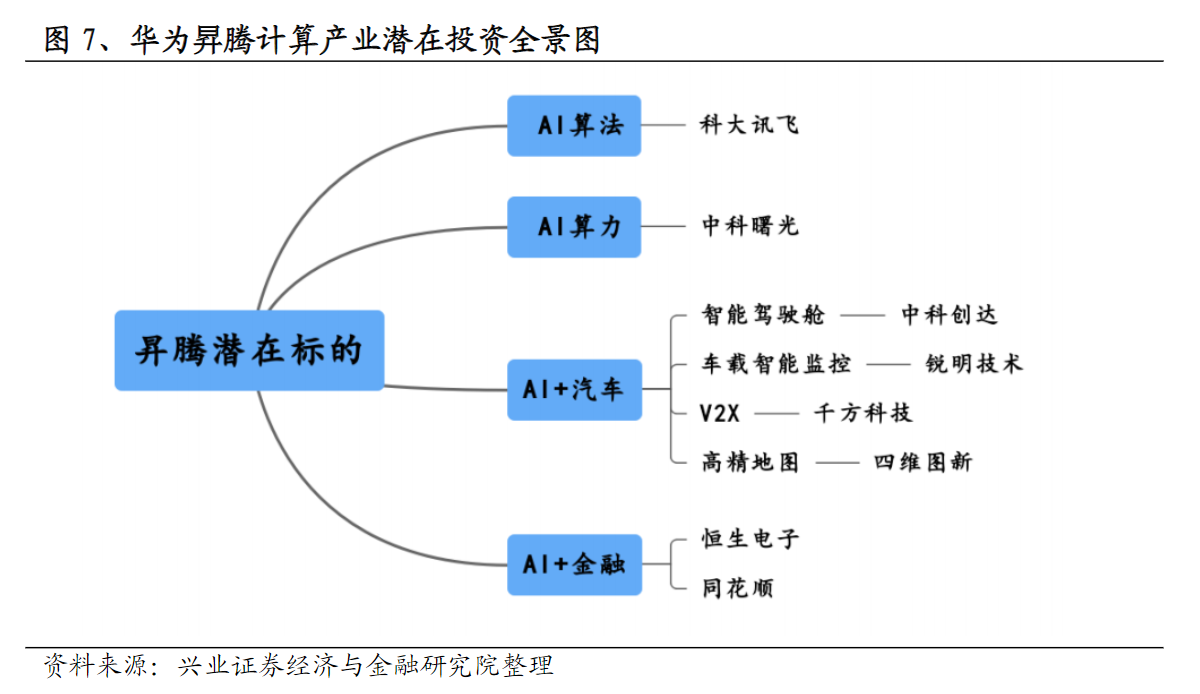
具体业务如下:科大讯飞国内人工智能龙头,长期从事语音及语言、自然语言理解、机器学习推理及自主学习等核心技术研究,技术水平处于国际前沿。2018年,公司与华为签署战略合作协议,目前双方主要在ICT基础设施产品、智能终端、以及办公IT领域开展战略合作。
中科曙光国内高性能计算领域领军企业,背靠中科院,提供从高性能计算机、通用服务器、存储、安全到数据中心等ICT基础设施产品。公司推出的容器化人工智能开发平台解决方案聚焦实际算法的优化和迭代,促进人工智能技术在各行各业的快速落地。
中科创达面向全球市场的智能操作系统产品和技术提供商,是华为的专业技术供应商,合作涵盖智能物联网、智能视觉及智能计算机。公司能够帮助华为构建基于昇腾芯片的应用生态。锐明技术为车载智能监控龙头,市占率全球第二。公司用于车载设备视频处理和人工智能的主芯片主要由华为提供。
千方科技国内智慧交通、智能监控龙头,近年来持续布局V2X。公司与华为联合推出的“千方-华为交通云解决方案”有效解决传统IT基础设施运行效率低下的问题。四维图新国内导航地图产业的开拓者,正致力于自动驾驶地图、高精度定位、云服务平台及车规级芯片等业务。2019年,公司与华为签订合作协议。目前,双方的合作领域主要在面向B端的导航电子地图、自动驾驶地图、V2X等方面。
恒生电子为国内领先的金融软件和网络服务供应商,聚焦金融行业。近年来,公司致力于推动金融机构从数字化、互联网化向智能化迈进,推出多款金融人工智能产品。同花顺为国内互联网金融科技龙头,近年来,公司积极探索、开发基于人工智能、大数据、金融工程等前沿技术的产品及应用,并形成新的业务模式和增长点。
中信证券杨泽原等人在2月16日发布的研报中表示,北京计划支持头部企业打造大模型,算力可能需要进一步扩容,带来服务器增量空间,其中拓维信息作为华为昇腾核心合作伙伴,2022H1昇腾硬件出货量第一,有望核心受益。建议关注拓维信息、神州数码等华为昇腾生态圈核心厂商。
具体来看,拓维信息是首批昇腾授权的人工智能计算硬件生产合作伙伴,其AI训练服务器可搭载8张昇腾910,提供2.56P FLOPS的FP16算力,目前已应用于长沙人工智能创新中心、重庆人工智能创新中心、全国一体化算力网络国家(贵州)主枢纽中心等项目中。据公司披露,2022年上半年,拓维信息昇腾计算硬件出货量位列华为昇腾合作伙伴排名第一。
华为昇腾采用自家的达芬奇架构,内部主要有三种类型的计算模块等。昇腾团队将计算分为了Scalar、1D、2D、3D这四种。然而业内人士指出其亦有缺点,1D Vector Unit可类比于SIMD指令。这种Unit可以完成网络训练和推理中的大部分算子,但其缺点是难以利用DNN中常见的数据的复用性。