Meta的首席人工智能科学家、卷积之父杨立昆这样评价ChatGPT大行其道引发的硅谷巨头军备战,“没有人比其他人领先超过两到六个月。”
他还给ChatGPT泼了盆冷水,在1月底的小型聚会上杨立昆发出讥讽:就底层技术而言,ChatGPT并不是多么了不得的创新,就是一个组合得很好的产品而已。
不久之前,他的东家Meta所推出的类ChatGPT语言模型Galactica遭遇了同谷歌巴德一样被群嘲的命运,因在公开场合出现错误,Galactica上线短短三天后就被喷下线。谷歌方面因为巴黎活动上聊天机器人巴德的一处失误,市值蒸发了1000亿美元。
在ChatGPT引发的这场谷歌“背刺”微软大战中,为科学评估谁的技术更为出色,业内已进行过一些测试。
比如今年1月,在一名谷歌工程师的帮助之下,《经济学人》向ChatGPT和谷歌尚未推出的基于Lamda模型的聊天机器人巴德提出问题,包括美国数学竞赛中的10个问题和美国离校生考试中的10个阅读问题,为了增加趣味性还要求每个模型提供约会建议。
谷歌的人工智能在数学问题表现上更优,正确回答了五个问题,而ChatGPT只正确回答了三个。二者给出的约会建议参差不齐,ChatGPT在常识问题上的准确率更高。
又过了几天,母公司OpenAI对ChatGPT进行了更新,后者的数学能力得到提高。1月30日再次测试时,ChatGPT已与谷歌模型在数学题目中的表现打成平手。
已经被广泛普及的一个事实是,ChatGPT背后的GPT模型是在超大语料基础上预训练出的大语言模型(LLM),但凡大模型都有极高的训练成本,会导致知识更新的困难,ChatGPT采取的训练方式尤甚,而ChatGPT的数学能力却能以日为单位进化,足以说明潜力之大。
纵然如此,ChatGPT也并没有同谷歌的语言模型拉开太大差距。
亿级用户在使用ChatGPT时,这个风靡全网的工具继续得到了优化迭代,但全球每天会发生100亿次的搜索查询,占比9成的谷歌搜索也在以日为单位迭代。在硅谷巨头财务现状江河日下,成本效率比以往任何时候都“更加重要”的当下,一切搜索引擎的更改都无法直接带来效益,谷歌和微软在这场游戏中真正需要的会是什么?
很多公开资料可以轻松查阅到谷歌与OpenAI最近5年在语言模型领域的发展时间线。
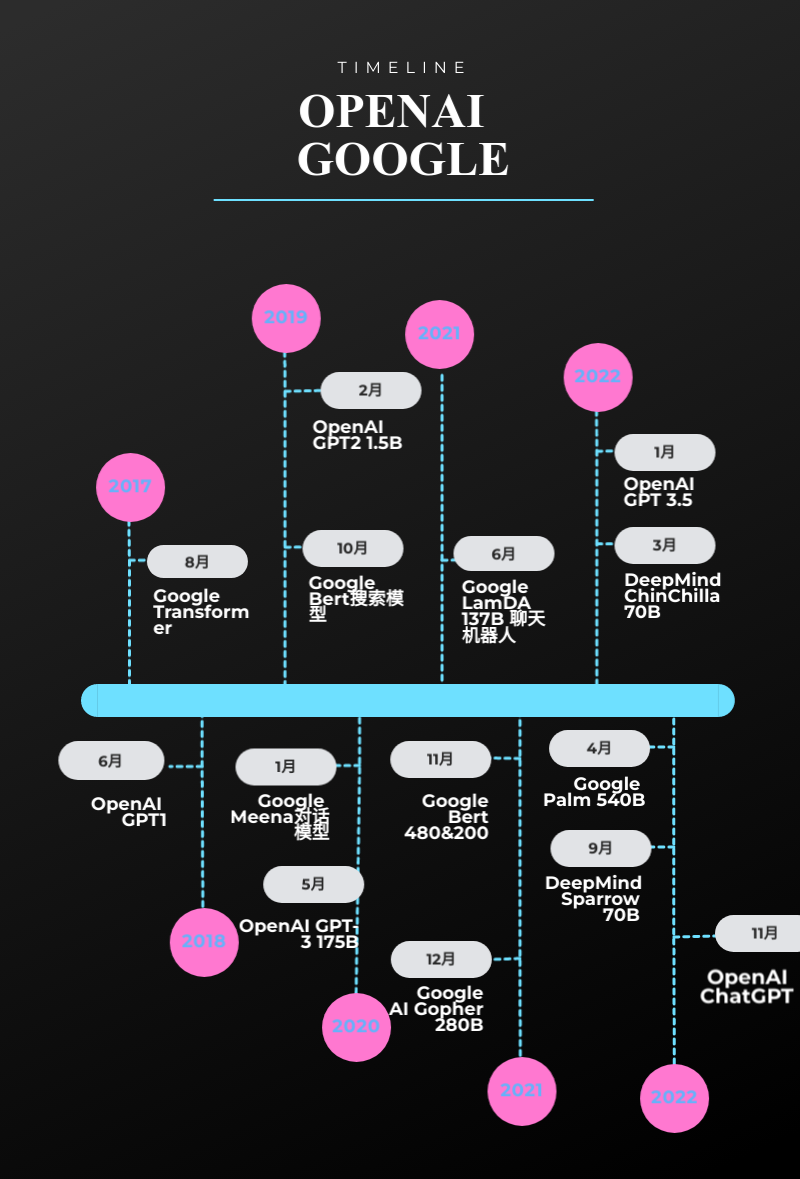
今年年初,谷歌AI掌门人杰夫·迪恩用万字长文做了谷歌2022年在AI领域的总结报告,报告内容简单概括即:谷歌在生成式AI、大型语言模型(LLM)等领域硕果累累,没有任何一项研究进展落后于OpenAI的DALL-E和ChatGPT,但这些成果都存在于内部研究,没有形成完整的部署和变现上的落实。
有观点指出,这几年中,谷歌有点像沈向洋时期的微软,手握曾经最强大的AI资源,研究论文一篇接着一篇,但从头到尾不发布任何有影响力的产品。
但为什么会变成这样?安于现状的谷歌是错判了微软和OpenAI的战力,还是对自己在搜索引擎的主导地位有深层次自信?
优等生为什么不交卷?
本时代最伟大的人工智能公司谷歌仍然拥有绝对实力。
在2019年到2021年两年时间里,谷歌人工智能个各大部门在抗议声中度过,但也从未落下对技术的锐意探索。
事实上,谷歌2017年提出的Transformer模型为今天这场游戏制定了规则,也是谷歌展现出了更丰富更准确的为大模型寻找能力提升的办法。
首先,谷歌察觉大模型是竞争的关键并不晚于OpenAI。
在OpenAI的GPT-3惊艳世界不到一年之前,2021年1月,谷歌推出了1.6万亿参数的Switch Transformer,这个超级语言模型让谷歌洞察到了稀疏多模态结构的价值。谷歌的研究人员当时表示,希望够激励稀疏模型成为一种有效的架构,并鼓励人们在自然语言任务中多考虑这些灵活的模型。OpenAI的GPT系列一直在密集模型的道路上狂奔,已有传言称,尚未发布的GPT-4可能是第一个以稀疏为核心的大型AI模型。
更关键的是,谷歌还提前于OpenAI意识到了超大规模语言模型的非必要性。2021年10月,谷歌提出了一个新的语言模型Flan-T5,它的模型结构和GPT相似,但比OpenAI在2020年5月发布的GPT-3(也就是ChatGPT的前任)的模型参数有大幅降低,却表现更佳,通过这一模型,谷歌探索到通过更多的监督数据能够降低模型规模,进而拿到更好的模型效果。
2022年10月,谷歌将语言模型Flan-T5开源,用30亿参数跑基准跑赢了GPT-3的1750亿参数。
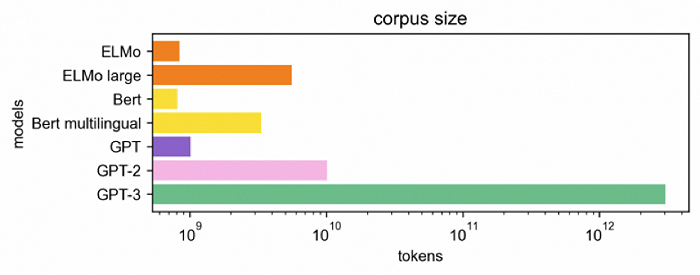
现在的OpenAI也洞悉了这一点,开始避免模型“越大越好”的方法,希望专注于模型本身的质量,据悉,尚未面世的GPT-4的大小会与GPT-3大致相同。
OpenAI的成立本身,就承载着一群意欲打破谷歌在人工智能领域垄断的青年才俊集体愿景,因此这家公司与谷歌的竞争一直摆在明处。

这场能力相近的游戏中,谷歌在技术前瞻性上更优,OpenAI则依靠执着取胜。萨姆·奥特曼从YC孵化器辞职之后,全力带领OpenAI以产品为导向闷头苦干,一干精英在扩大模型和密集模型的道路上一往无前,反复之处无外乎精调方式的细节。
谷歌方面,思路活跃前卫,但在大的路线上屡经转换:走稀疏模型路径的万亿参数Switch Transformer影响较低,并未得到坚持投入;被反复打磨的Flan-T5模型虽然表现胜于GPT-3,但优化速度缓慢,在此期间OpenAI已经完成了对ChatGPT的训练。
2022年9月,谷歌姐妹公司DeepMind的麻雀模型初现,走上了小模型参数打败精调的道路,与谷歌看重的LaMDA和PaLM模型在规模探索上有明显思路区别,但一方面谷歌碍于与DeepMind之间的关系,另一方面在几条路径之间谷歌并未迅速确定麻雀就是最优解,这些导致麻雀无法迅速转换为产品。当时间又过去4个月,OpenAI的ChatGPT已经星火燎原。
精力分散是谷歌的宿疾。
搜索巨头一直欠缺制定产品战略的能力,谷歌员工可以用很低成本启动一个全新项目,但如果一段时间后不达预期,项目就会立刻遭遇腰斩。有开发者专门为谷歌所关闭的产品成立了一个叫“Killed by Google”的网站,共有275个产品位列其中,包括谷歌云游戏平台Stadia。
在微软和谷歌两家巨头担任过产品经理的Jackie Bavaro去年撰写了一篇有影响力的博文分析谷歌的产品策略,她认为谷歌的公司文化鼓励团队提出自己的想法,公司的最高级OKR(目标管理法,谷歌的内部考核制度)并不凌驾于其他OKR之上,这看似很好,却会以牺牲掉中型产品和员工精力为代价。反观微软,产品负责人非常清楚产品取得成功的条件,每个获批项目必须与微软更核心的战略支柱紧密相关。
在微软决定改道AI之后,连其培育工业基因的唯一种子——工业元宇宙项目都可以立即解散,软件巨头与谷歌之间的专注度高下立见。