我们国家什么时候才可以研发出像ChatGPT这样牛逼的人工智能产品?有人说拿来主义,复制一份不就好了吗?话糙理不糙,因为这确实是最快的一个渠道,但是ChatGPT这种产品的4个先决条件,我们已经满足了3个,其中有一个我个人感觉确实暂时拿不动!
下面我直接列举了8个问题,应该可以回复你关于ChatGPT的大多数疑问,而与此同时,当你看完之后,你应该对ChatGPT会有一个全新的认识,你也会明白,为什么我说有一点暂时拿不动!
不废话直接上干货,先看一下GPT这个模型的一个时间里程碑:
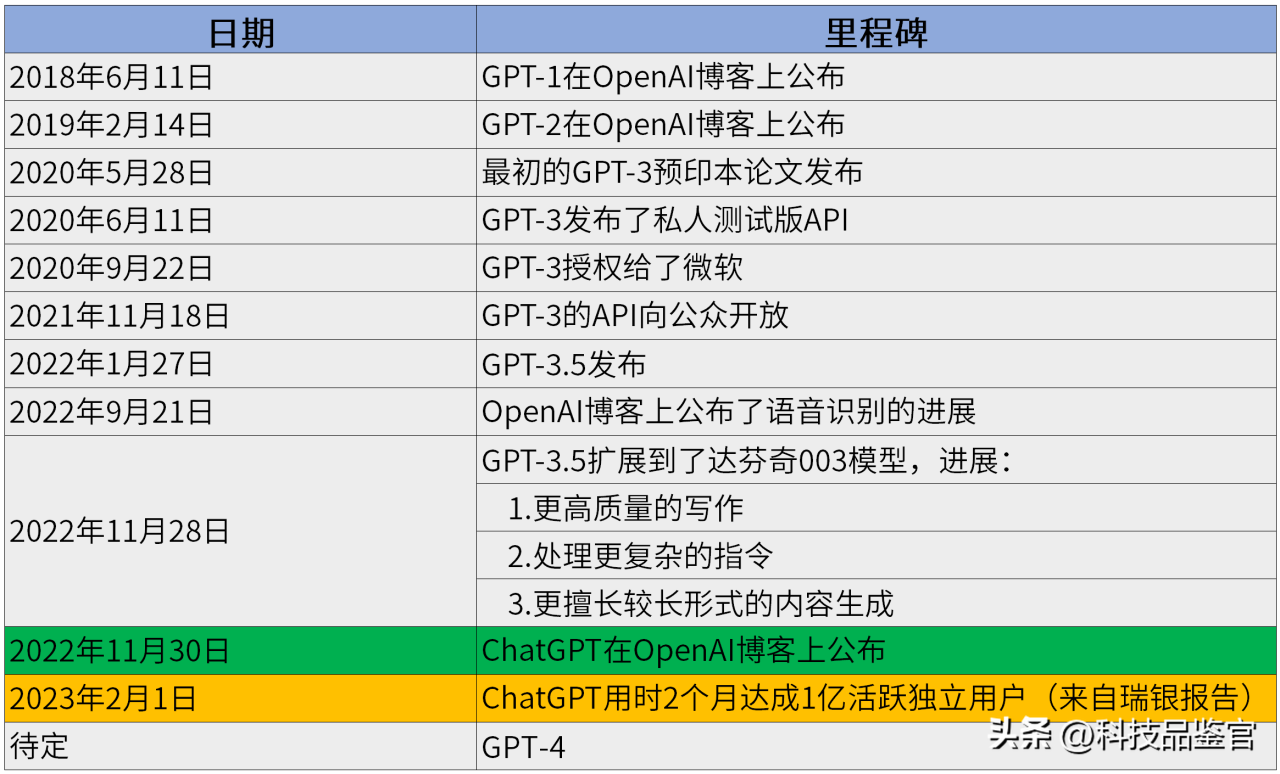
OpenAI从2018年开始研发GPT模型,到2022年11月30日正式发布基于GPT3.5模型的ChatGPT聊天机器人,期间总共历时大概四年半,进入了2023年的2月份,ChatGPT只用了5天就吸引了100万订阅用户,而到今天大概只有两个月的时间,它更是达成了1亿活跃独立用户的历史最快成绩,由此可见,这个玩意儿确实是革命性的,比尔盖茨更是称赞它的出现不亚于电子计算机或者是互联网的出现,其影响力可见一斑。
你的可能疑问
问:ChatGPT可以访问互联网吗?
答:ChatGPT和其他基于Transformer(转换器)的大型语言模型是无法访问互联网的,但是想让人工智能领域里的模型去访问互联网,应该是一件很简单的事情,这一层是可以单独构建的,后续很有可能会出现一个WebGPT的概念。
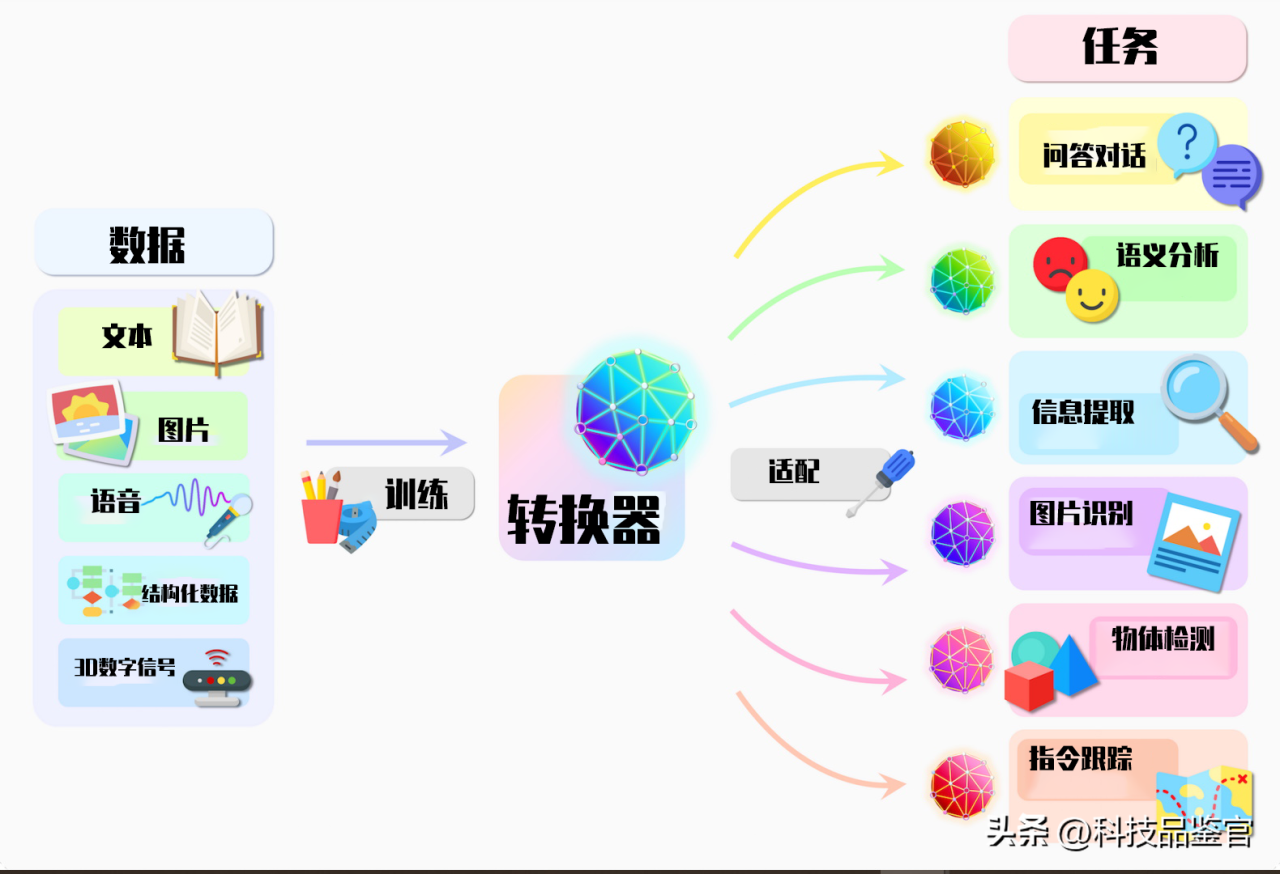
简单说一下什么是transform模型,它是一种神经网络,可以通过跟踪序列数据中的关系,比如说某句话中的单词来学习上下文,它会应用一组不断发展的数学技术,我们可以称之为注意力,或者是自主注意力,去感应遥远数据元素中的那种微妙的相互影响与依赖关系,放张图片,看一下transformer模型的神秘面纱吧:
问:ChatGPT怎么收费?
答:好日子已经到头了,从发布到现在两个月的时间,基本上都是可以免费使用的,但是从2023年的2月份左右开始,open AI将会发布一个plus计划,每个月大概需要20美元,当然好处也是多多,那就是你的请求量可以很大,而且可以给你更快的响应速度,当然,如果x的GP有一些新的功能的话,你也是可以优先使用的,所以花钱也是有花钱的道理,但是我相信一定会爆卖的。
问:ChatGPT的“智商”到底怎么样?
答:首先要说的是是GP3.5模型已经通过了美国律师资格考试,注册会计师的考试以及美国医疗执照的考试,试问美国有多少的人可以同时通过这三项考试呢?另外,门萨国际的前主席曾经对GPT3的智商进行了估计,他估计ChatGPT在语言智商的测试环节中应该可以取得150分的高分,而实测的结果是147分,在这里我给大家再列举一张图,看一下GPT-3已经在哪些行业取得了哪样的成绩:
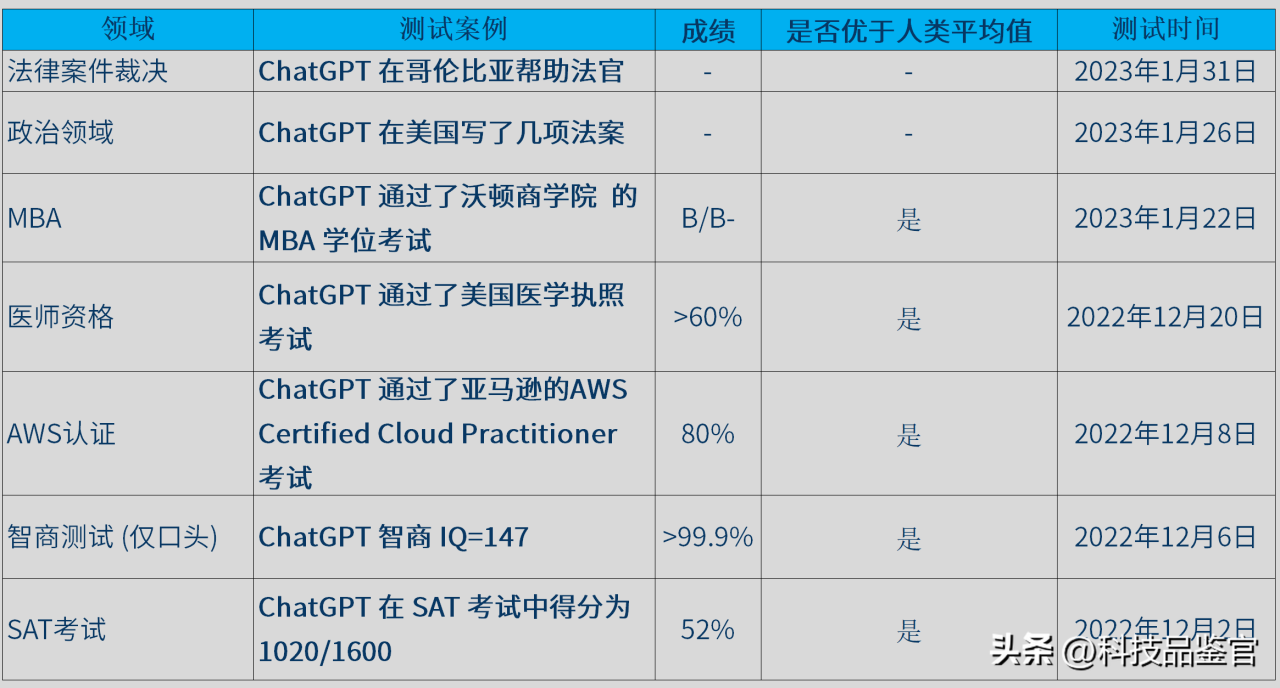
看看这个图是不是感觉ChatGPT强大的有点离谱啊,他可以立法,他可以判案,他可以通过商学院的MBA考试,他可以考取医师资格证书,他可以攻克亚马逊的AWS认证,在口语测试中智商更是高达147,而且在这几个案例中他的表现都已经优于了人类平均值,那这就基本可以验证一点,从综合的角度来看,ChatGPT的智商已经在人类中平均值之上,照这个势头发展下去,用不了几年,多数人在ChatGPT面前都是个“傻子”!
问:ChatGPT可靠吗?
答:其实上面的一个问题已经给出了一个答案,那就是在信息的正确率上,ChatGPT在多数情况下是对的,但是有大概百分之二三十,信息就不那么可靠了。前两天ChatGPT不是也出现了一个小小的“笑话”吗?有人让他同时评价川普和拜登,但是他在对拜登进行大加赞赏的同时,却拒绝评价川普,这就说明ChatGPT具体会给出怎样的答案,它背后的人是是有决断权的。另外OpenAI自己也表示,他们希望通过现实世界的经验与反馈,学习如何研发真正有用和可靠的人工智能,他们表示ChatGPT目前还没有那个实力,在任何事情上给出值得信赖的答案。
问:ChatGPT是否比GPT-3更强大?
答:这地方大家可能就有一个误区了,其实ChatGPT是GPT3这个模型的一个实际应用案例,我们用户是可以真正的看到ChatGPT的,因为它有比较漂亮的用户界面,我们可以实时的跟它进行交互,而对于GPT-3而言,我们只知道它是ChatGPT的一个基石,其实它可以给我们提供更多选择的对话模型以及大型语言模型库,说白了他们的关系就是,没有GPT-3就没有ChatGPT,但是没有ChatGPT,GPT-3依然存在。打个更加贴切的比方,那就是,如果你玩游戏的话,你应该知道虚幻引擎, GPT-3就是那个虚幻引擎,而ChatGPT则是基于虚幻引擎上实际开发出来的一个游戏而已。
问:我们可以在自己的本地运行ChatGPT或基于GPT-3模型进行训练吗?
答:理论上当然是可以的,但是这几个条件你看一看就可以了,对个人而言没有希望,对小公司而言也没有希望,只有大型的公司才有可能做到:
第一,硬件投资,为了能够训练1750亿个参数的GPT-3模型,你需要使用到大概1万张显卡以及285,000个CPU的核心,这种投资可以吓退99.99%的人,即使OpenAI自己也没有能力打造这套硬件设施,它是花了10亿美元从微软云上租用来的!猛不猛?爆不爆?
第二,人员配备,我们训练的目标肯定不能去训练别人已经训练过的东西,也就是别人吃过的东西,我们肯定不会再去吃了,所以为了训练出新的东西,我们需要世界上最聪明的博士级数据科学家,这又是一笔钱,没有几亿美元是拿不下来的,而且其实有钱也不一定能够请到这样的人。
第三,数据收集,凡是涉及到人工智能模型的训练,就需要海量海量的数据,数据从哪里来由谁来收集,这都是不确定的,又是一笔时间和金钱。
第四,真正的训练,假如说你是世界的超人,123条你都已经满足了,但是真正对模型训练也是需要花费时间的,像GPT-3这种规模的模型,需要大概9~12个月的时间,而且中间如果出现了一些问题,还需要对他进行多次训练,时间成本也是很高很高的。
问:ChatGPT是否会偷偷的复制保留数据?
答:其实你的数据,ChatGPT都看不上,他之所以现在如此强大的核心原因是,在大量时间的训练之后,它已经在数以万亿计的各种各样的词之间建立了关联,并保留了这些词汇之间“微妙”的连接,它早已经将原始数据都已经丢失了,也就是你知道的,他全都知道,你不知道的,他知道的更多,它能够在各种各样的问题上给出人性化的答案,并不是他记住了这些答案,而是建立了你问题所提出的那些文字之间的微妙的链接,基于这些链接,亦或是说神经网络或者是神经元吧,它可以真正地以接近人类大脑的方式给出自己的回复,一句话,他的强大不是靠死记硬背,所以就谈不上偷偷复制保留数据的问题了。
问:ChatGPT有类人人意识吗?
答:我相信这个问题好多人应该都挺关注的,大家可能都觉得ChatGPT如此强大,很有可能已经有了类似于人类的意识,其实现在想一想,完全没有可能,只要把电一断,一切凉凉。在上个问题中已经说了,它在数以万亿计的词语之间建立了微妙的关联,也就是它应该是一个非常强大的文本预测器,也就是在经过训练之后,当接收到新的文本之后,它可以预测到下一个文本,也就仅此而已,所以现在这个模型啊,我们暂时还不用担心,它完全是静态的,没有思想与意识。
阶段性汇总
其实看过了这几个问题之后,我想各位应该对ChatGPT,从科学的角度上,应该有了一个入门级的认知,如果让我总结上述几个问题得出的结论的话,那就是:
使用全球顶级的人才,使用全球顶级的算力,使用全球海量的数据,使用以年为单位的训练时间,去构建出,全球以万亿计的词汇的连接,ChatGPT当前在所有问题上的答案,都是以问题中的文本作为连接的入口,然后给出它的连接能够关联出的预测,而当下这个连接有多复杂,我们就只需要记住一个数字,1750亿。