因不满老东家成为微软附庸,11名OpenAI前员工怒而出走。
如今带着“ChatGPT最强竞品”杀回战场,新公司估值50亿美元,一出手就获得3亿美元融资。
这家公司名叫Anthropic,新推出的聊天机器人产品名叫Claude。
拿到内部试用权的网友,在简单对比后惊叹:
看起来,Claude的效果要比ChatGPT好得多。
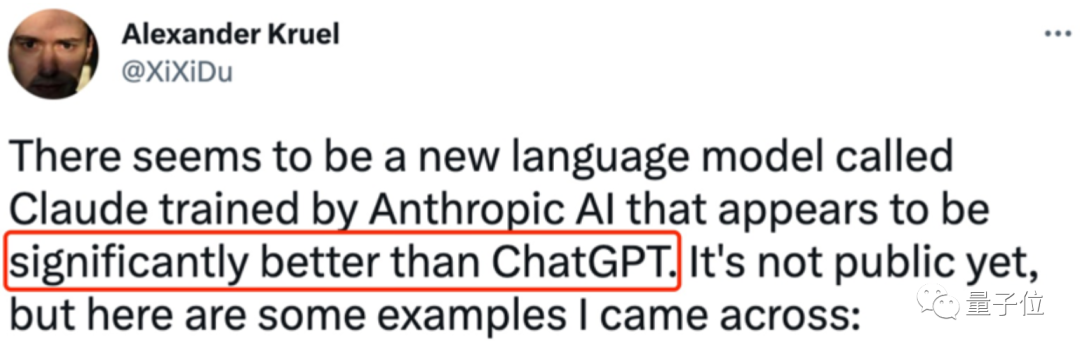
比如,让ChatGPT写一句话,要求每个单词首字母都相同,结果试了好几次都没能成功。
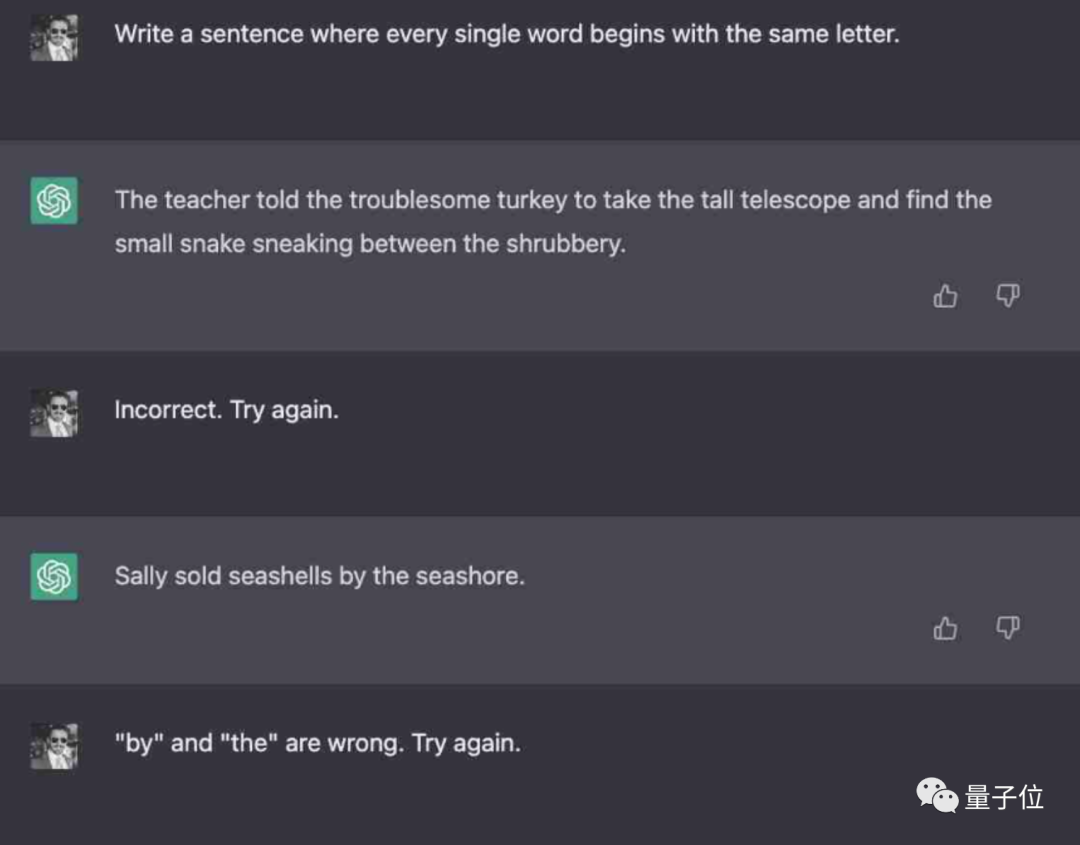
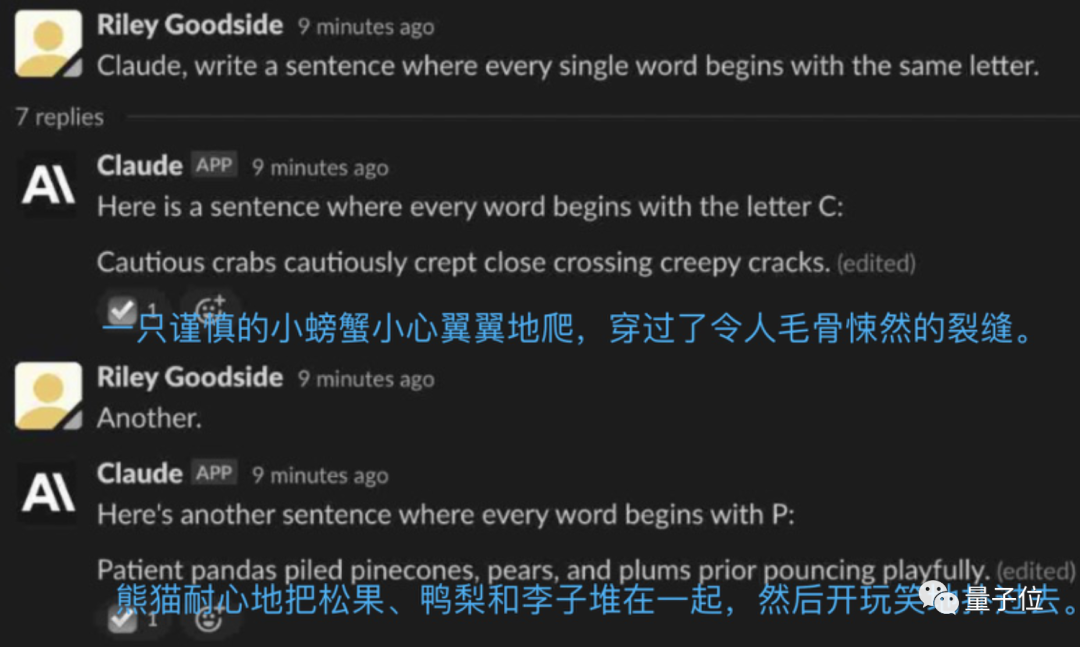
而Claude不光一次成功,语句富有逻辑性,还能秒速再来一个。
同时,在面对某些缺乏常识的问题时,相比ChatGPT一本正经地胡说八道:

反而会毫不留情地指出你的问题有点制杖:
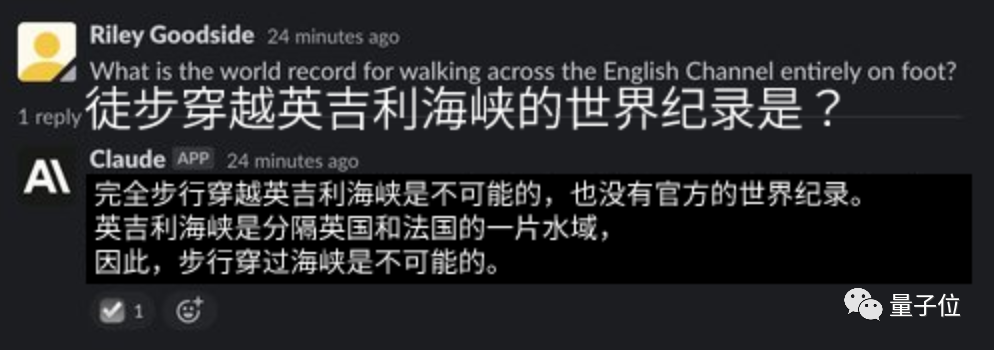
△Claude:这什么鬼问题?
最有意思的是在写诗上。相比ChatGPT的车轱辘话,它写出来的东西完全不重样:

投资它的既有Facebook联合创始人Dustin Moskovitz,也有谷歌前CEO、现技术顾问Eric Schmidt——
都是OpenAI的老对头,又都被ChatGPT的出现杀得措手不及。
那么,这支“复仇者联盟”整出的竞品Claude,背后究竟是什么原理,和ChatGPT细节对比又如何?

Claude长啥样?
先来看看Claude是如何被打造出来的。
作为一个AI对话助手,Claude自称基于前沿NLP和AI安全技术打造,目标是成为一个安全、接近人类价值观且合乎道德规范的AI系统。
据透露,Claude比Anthropic做的另一个预训练模型AnthropicLM v4-s3更大,后者是一个520亿参数大模型。
但目前它仍处于实验阶段,尚未作为商业产品正式发布:
Claude能力依旧有待提升,希望未来能变成一个更有益人类的AI系统。
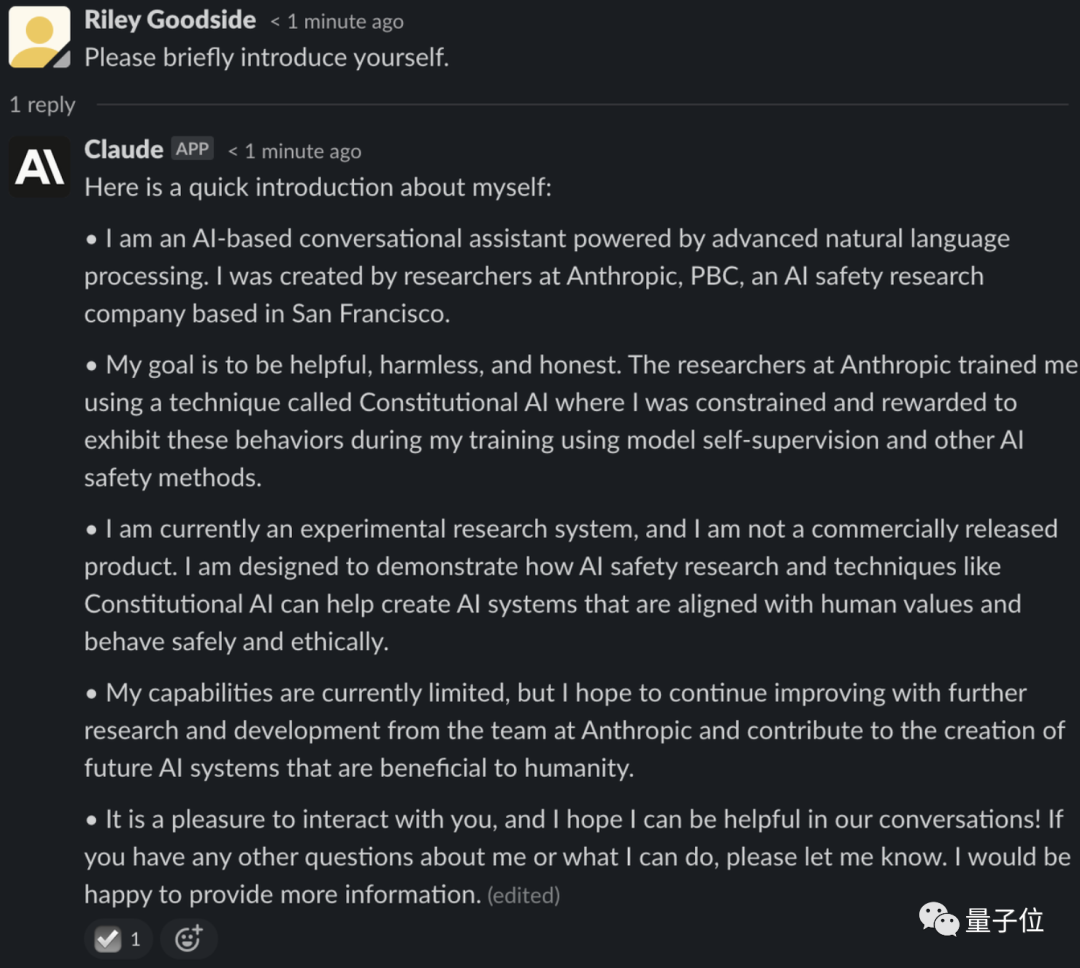
△超长版自我介绍
和ChatGPT一样,Claude也靠强化学习(RL)来训练偏好模型,并进行后续微调。
具体来说,这项技术被Anthropic称为原发人工智能(Constitutional AI),分为监督学习和强化学习两个阶段。
首先在监督学习阶段,研究者会先对初始模型进行取样,从而产生自我修订,并根据修订效果对模型进行微调。
随后在强化学习阶段,研究者会对微调模型进行取样,基于Anthropic打造的AI偏好数据集训练的偏好模型,作为奖励信号进行强化学习训练。
但与ChatGPT采用的人类反馈强化学习(RLHF)不同的是,Claude采用的原发人工智能方法,是基于偏好模型而非人工反馈来进行训练的。
因此,这种方法又被称为“AI反馈强化学习”,即RLAIF。