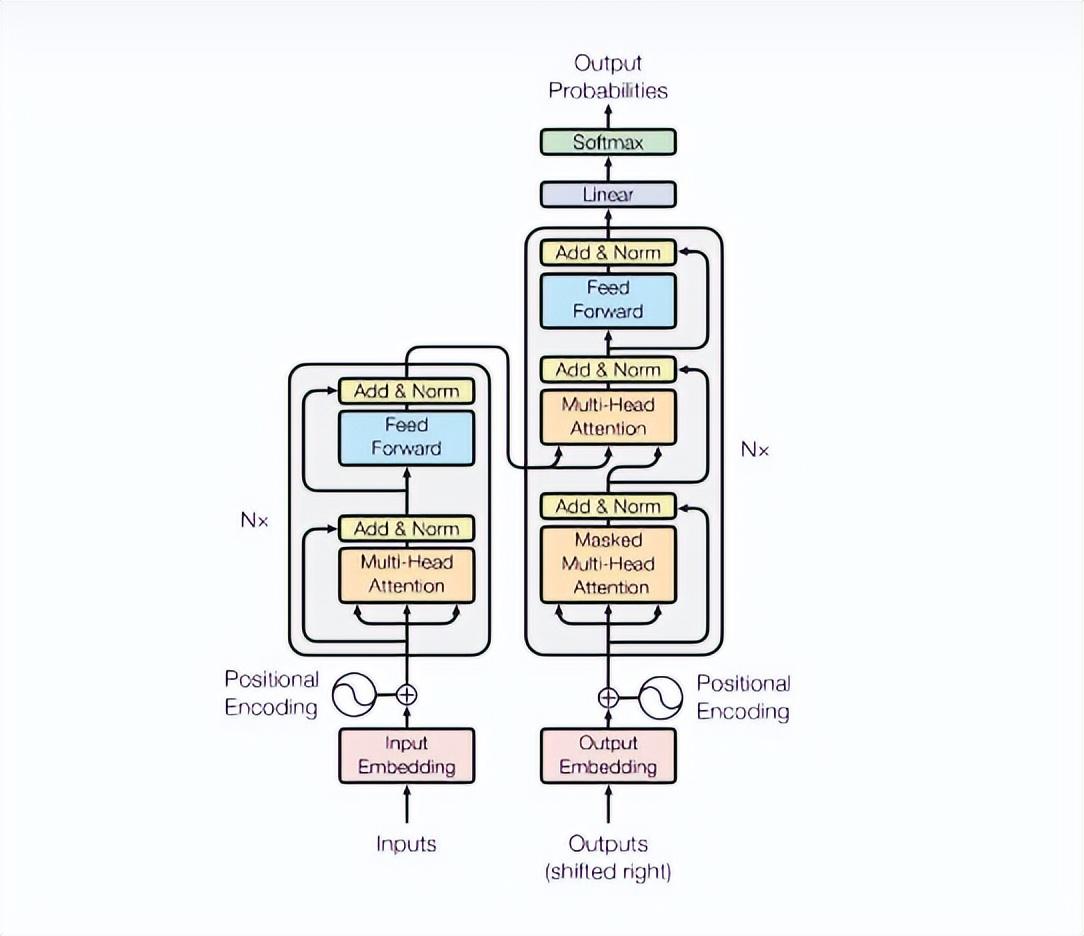
Transformer是一种用于序列到序列(Sequence-to-Sequence)任务的神经网络模型,例如机器翻译,语音识别和生成对话等。它使用了注意力机制来计算输入序列和输出序列之间的关系。

Transformer的主要优点是它可以并行地处理输入序列中的所有位置,因此在训练和推理时都有着很好的效率。此外,Transformer没有使用循环结构,因此它不会受长序列的影响,并且在处理长序列时不会出现梯度消失或爆炸的问题。
相比之下,基于循环的模型(例如基于LSTM的模型)可能在处理长序列时会出现问题,因为它们必须逐个处理序列中的位置,这会使它们的训练速度变慢。另一方面,Transformer在处理短序列时可能不如基于循环的模型那么准确,因为它没有循环结构可以保留先前位置的信息。
总的来说,Transformer是一种很有效的模型,特别是在处理较长的序列和并行化计算时。它已经成为了NLP(自然语言处理)领域中许多序列到序列任务的首选模型。
Transformer模型最初是由Vaswani等人在2017年提出的,并且在自然语言处理(NLP)领域得到了广泛应用。
其中著名的模型包括:
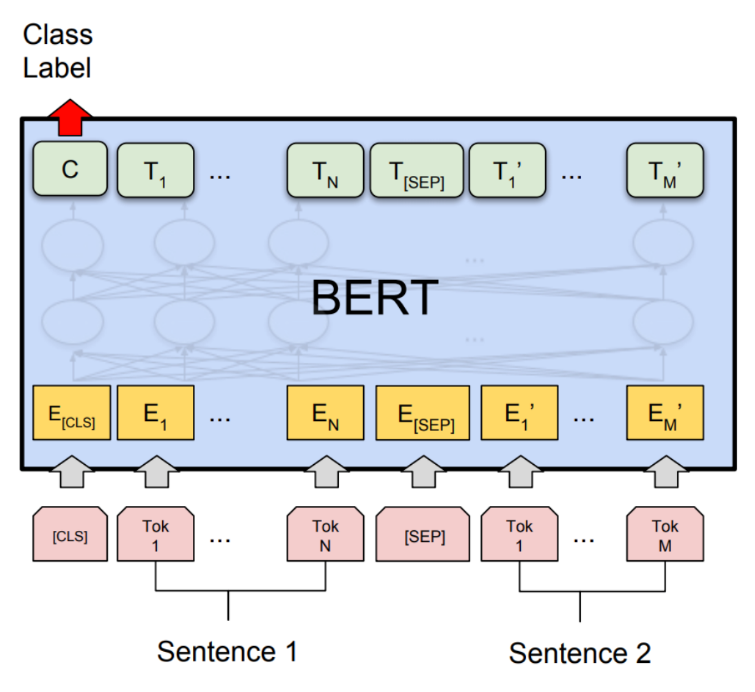
· BERT(Bidirectional Encoder Representations from Transformers):这是一种语言模型,它能够在许多NLP任务中取得最先进的性能。
· GPT(Generative Pre-training Transformer):这是一种自然语言生成模型,能够生成各种文本,包括新闻文章,小说和代码等。
· Transformer-XL:这是一种扩展的Transformer模型,能够处理更长的序列,并且在很多NLP任务中取得了最先进的性能。
除了NLP领域,Transformer也被用于其他领域,包括计算机视觉,音频信号处理和强化学习等。
Transformer是一种非常强大的神经网络模型,但是它也有一些局限性。
其中一个局限性是它依赖于输入序列的长度。由于Transformer使用注意力机制来计算输入序列和输出序列之间的关系,因此它可能难以处理较长的序列。虽然有一些变体,例如Transformer-XL,可以更好地处理长序列,但是它们仍然存在这个问题。
另一个局限性是Transformer模型对于处理序列中的时间依赖性不太友好。由于Transformer没有使用循环结构,因此它无法保留序列中先前位置的信息。这意味着Transformer在处理序列中的时间依赖性时可能不太准确,例如在处理语音信号时。
总的来说,Transformer是一种很有效的模型,但是它并不是万能的。在选择模型时,应该考虑序列的长度和时间依赖性等因素,并确定Transformer是否是合适的选择。