5月17日,据官方消息,Reddit 已与 OpenAI 达成协议,允许其使用自家内容训练聊天机器人及其他产品。合作宣布后,Reddit股价在盘后交易中上涨11%。
图源:X
合作的互利共赢,OpenAI在官网中有所介绍:
OpenAI能用上Reddit的实时内容:自家AI 工具由此能够更好地理解和展示 Reddit 上最新话题的内容,因为OpenAI可访问得Reddit数据 API,将提供实时的、结构化的、独特的内容。
Reddit能用上OpenAI的AI技术:Reddit 将建立在 OpenAI 的 AI模型平台上,将使Reddit为redditor和 mod带AI驱动的全新功能。
最后,OpenAI将成为Reddit的广告合作伙伴。
OpenAI的首席执行官Sam Altman持有Reddit 8.7%的股份,此前还是Reddit的董事会成员。所以OpenAI为了避嫌,强调此次合作是“由OpenAI的首席运营官(Brad Lightcap)领导”,并“由(OpenAI)独立董事会批准”。Altman作为OpenAI董事会成员,据TechCrunch,本人在此次决定上采取回避姿态。
此次合作的梗图诞生:Altman这一出,属于是左手倒右手,一看都是自家人。
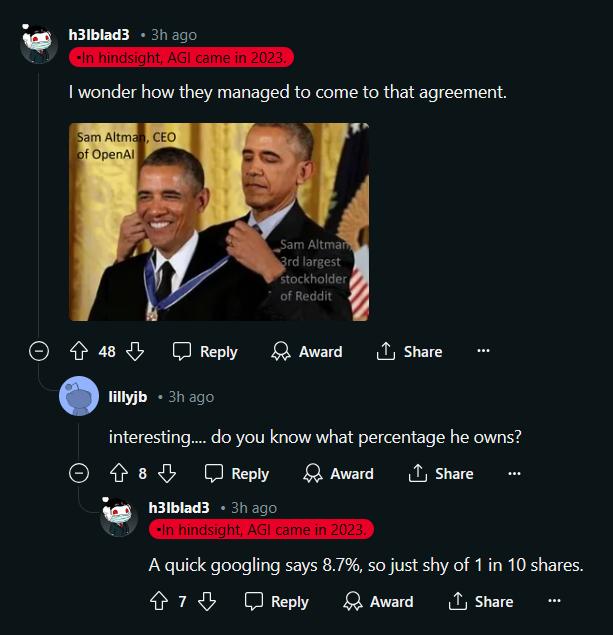
图源:Reddit
我想知道这次合作具体怎么谈成的。
很多网友似乎不太理解Reddit内容对于大模型的价值,纷纷表示Reddit会让ChatGPT变得“不干净”。
熟悉“贴吧”内容调性的网友们马上炸开了锅,有人马上弃坑:Claude不比你GPT香?

图源:X
大本营Reddit平台上的悲观发言:把各位贴吧老哥的发言喂给大模型,AGI的进展立马倒退四年:
图源:Reddit
OpenAI的模型要用贴吧上科技板块的数据训练,看来对AGI的预测要推后四年。
有人也不明白了:Reddit至于那么差吗?
图源:Reddit
只有我比较开心?Reddit上有用的内容也不少,如果能用AI查询,岂不美哉?
殊不知,前有论文证明“弱智吧”内容才是AI中文语料质量的高地,这波属于是网友信不过OpenAI技术大拿们的眼光了。
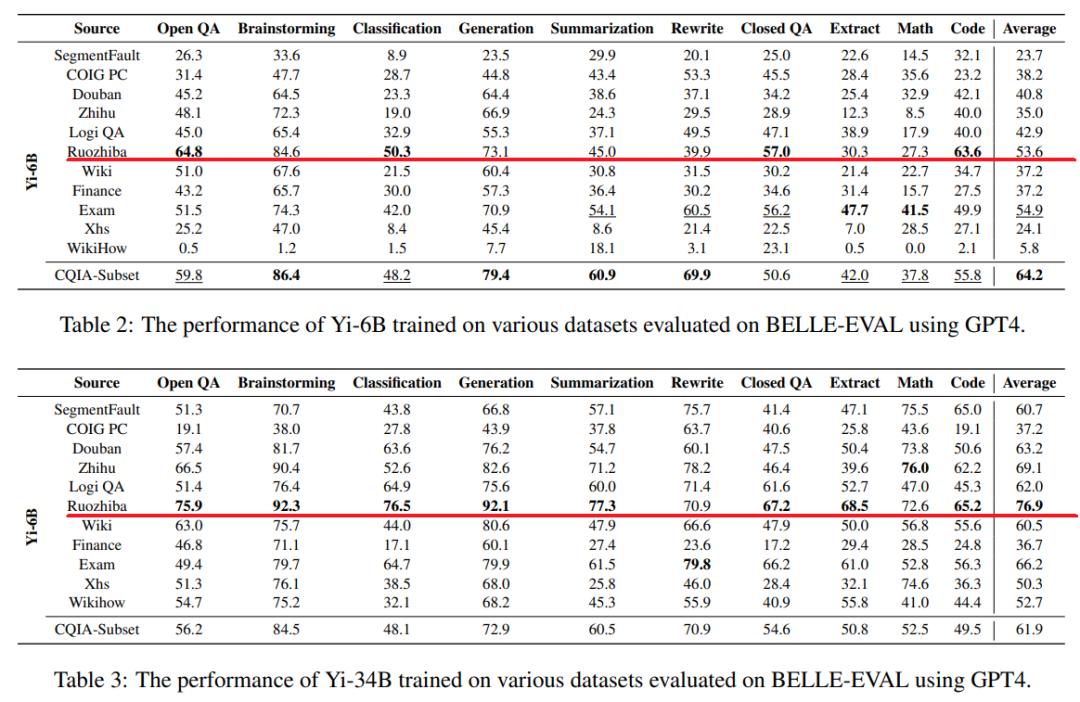
图源:论文
用平台数据拓宽收入渠道,曾遭大规模抵制
成立于2005年的Reddit,于2024年3月上市,目前并不盈利。据其最新介绍,Reddit日活跃用户为8270万。据Techcrunch,Reddit的平台帖子超10亿个,评论数超160亿条,用户生成的内容每天还在增长。平台也可以被看做AI公司训练模型的“金矿”。
此次合作也说明,Reddit依然在尝试不同业务,不希望过于依赖于广告收入。
OpenAI、谷歌等公司将Reddit的数据用于自家模型训练后,Reddit不甘“白嫖”,2023年6月,Reddit宣布将对开发人员访问其API收取高额费用。其对每5000万个API请求收取12000 美元的费用,在业内定价已经很高。
大树底下不能乘凉了。靠着Reddit发家的各种第三方应用及个人开发者没法挣钱,Reddit社区自此开启一场声势浩大的抗议。在海量用户的自发组织下,在6月12日开始瘫痪。超过8000个版块(类似于微博、贴吧的不同话题)都被版主设置成了“私人版块”,其他用户无法访问。
来源:The Verge
这场利益没有对齐的抗议很快又被自发终结。仅仅过了两天,大部分版块恢复运营。用户找不到平替之前,还得接着用Reddit。
Reddit官方下场“反白嫖”的最终目的很快落地——用平台内容向大模型公司收费。
2024年3月上市前,Reddit与谷歌母公司Alphabet还达成每年价值约6000万美元的交易,允许自家内容用于谷歌模型的训练。5月早些时候,Reddit公布的首份季报中,收入超过分析师预期。这表明,Reddit与谷歌的交易及其推动广告业务增长的努力,正在得到回报。

来源:路透社
为什么各家大模型公司都在抢着给Reddit送钱,真的找不到更好的语料吗?
数据“掘金”的终点,难道是贴吧?
OpenAI掌门人Altman最近在播客中提到,模型未来的进步,不应该依赖数据。但就目前阶段来说,数据仍然是当下各大玩家的必争资源。
根据大模型的尺度法则,即便模型参数和算力都不断提高,但是数据量和质量如果停滞不前,模型的性能也很难持续进步(见智能涌现文章,大模型闹“数据饥荒”,科技巨头进入灰色地带)。
3月在英伟达GTC大会上,黄仁勋对话Transformer七子时也有观点认为:高质量的模型需要的其实是高质量的数据,一味堆量是不够的。
外国网友还在担心,把过于负面的Reddit“贴吧语料”喂给AI会不会适得其反;中文互联网上,最好的大模型语料库真的就是贴吧——弱智吧。
这个结论来自三月底发布的一篇论文。研究团队发现,大语言模型目前能理解、执行复杂指令,回答也能做到准确流利。然而这些进步基本都发生在英语世界,中文大模型的若要进步,就需要基于独特的语言特征和文化深度,找到合适的数据集。