015年12月,OpenAI公司美国旧金山成立。萨姆·奥尔特曼(Sam Altman)和伊尔亚·苏茨克维(Ilya Sutskever)是OpenAI早期的重要成员。值得一提的是,特斯拉创始人马斯克也在其中。
伊尔亚·苏茨克维是人工智能领域的顶尖研究员,此前曾是谷歌的研究科学家,主要搞得就是深度学习,所以在新成立的OpenAI公司做这个方向的技术负责。
这里插说一下,什么是深度学习?
深度学习是一种基于人工神经网络的学习算法。人工神经网络这个概念,虽然听起来一副深不可测的样子,实际也没那么玄乎。就是模仿人脑神经元的运转方式来做数据分析。
举个例子,人是怎么识别一只猫的。

首先,我们看这个小动物的耳朵,直立着,尖尖的,而且在最尖端还有一小撮毛发。再看眼睛,大大的,而且有的时候还能收缩成一条垂直缝隙的瞳孔。鼻子和嘴巴也很有特点,这两个区域较为紧凑,上颚比下颚稍微长一些,嘴巴周围长有胡须。整个身躯呈流线型,颈部看起来很灵活而且比较细长。胸部和腹部都相对较小,四肢修长,后肢比前肢要长一些等等。
眼睛把看到的这些图像信息传递给大脑皮层,然后负责识别物体的神经元被激活,它们拿着这些输入的信息开始像记忆层去捞数据,也就是从已有的知识库中搜索与当前观察到的特征相匹配的信息。最后会给出这是一只猫的结论。
人工神经网络的工作流程也与之相似,先是要做训练。这一过程很像人类的学习过程。毕竟,如果我们从未见过猫,自然也无法识别它。在训练阶段,我们向人工神经网络提供大量的输入数据和对应的输出结果,让它学习并建立起输入与输出之间的关联。通过这种方式,我们告诉神经网络,当再次遇到类似的输入时,应该如何给出相应的输出结果。
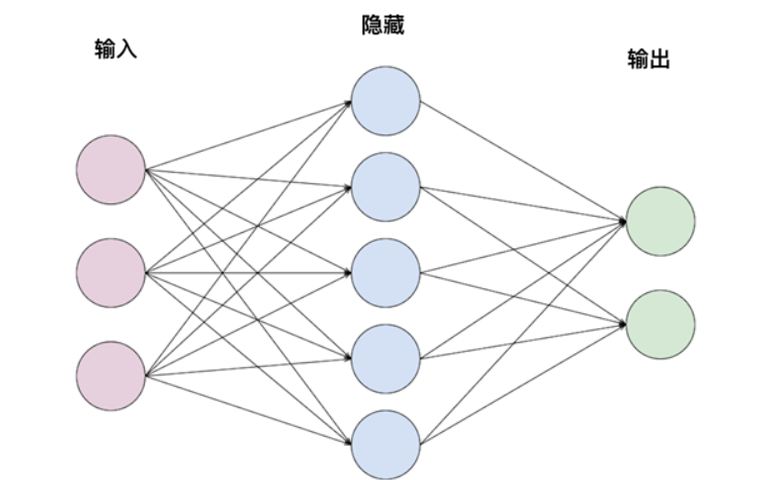
一旦训练完成,只要向人工神经网络提供相关的输入,它就能依据先前的学习结果迅速给出准确的输出。这样,人工神经网络就能够像人一样,通过学习和训练,不断提升自己的识别和判断能力。
再回到深度学习,识别猫这样的任务毕竟还是很简单的,只需通过几个输入对应一个输出即可解决。然而,面对更为复杂的任务,比如给出一套房子的装修方案,情况则大不相同。在这种情况下,输入可能极为繁多,初步的处理只能生成一层输出,但这仅仅是冰山一角。为了获得更为精确和全面的结果,这些初步的输出会再次作为输入,进入下一层神经网络进行进一步的处理。这个过程会反复进行,直到最终获得我们期望的装修方案。
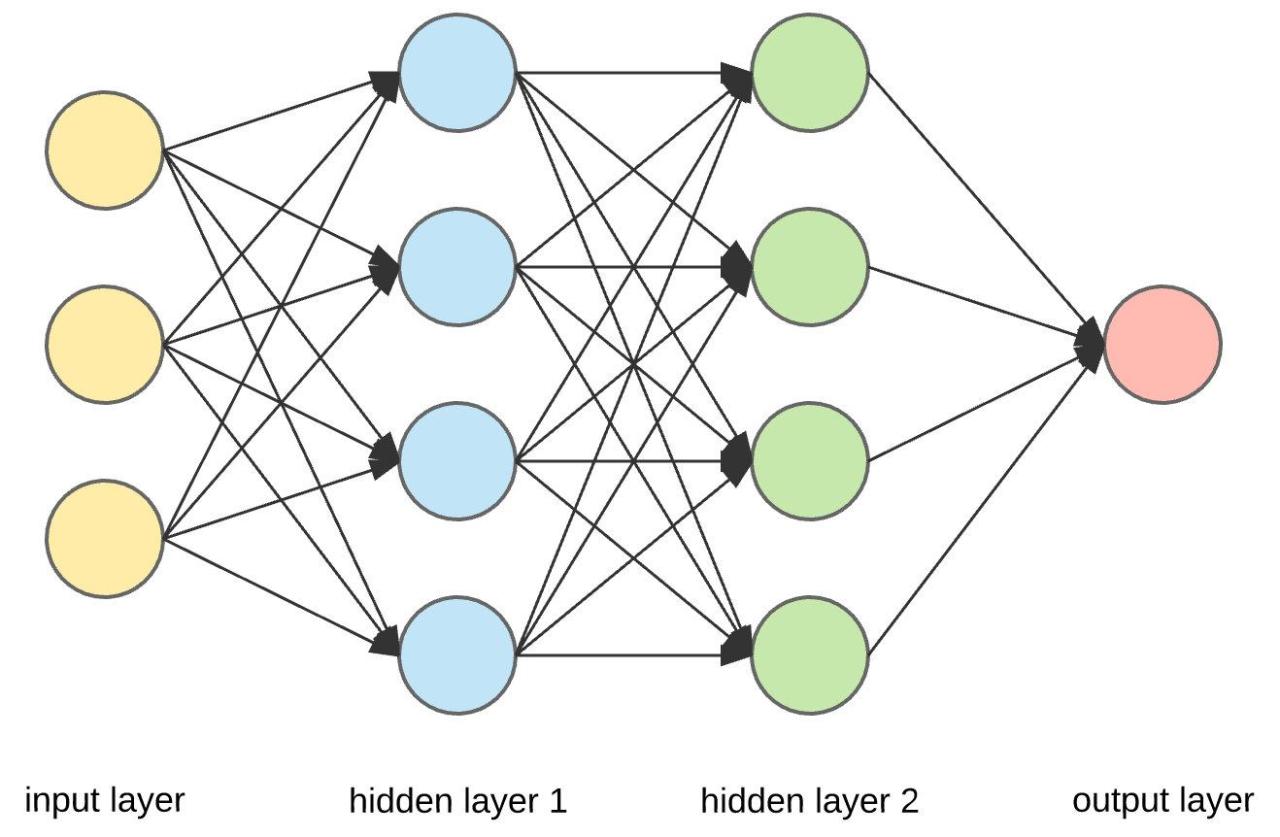
这种一层接着一层、不断深入的处理过程,正是深度学习所谓的“深度”所在。尽管深度学习的实现方式和技术细节可能更加复杂,但其核心的技术理念仍然与我们之前讨论的人工神经网络相吻合——即通过模拟人脑神经元的运作方式,自动提取和学习数据的内在规律和特征,以解决复杂的模式识别问题。
好了,搞懂了深度学习,我们接着来讲OpenAI公司。
OpenAI成立之初是一个非营利性的研究组织,它的目标是推动人工智能的发展,并确保该技术能够安全地造福全人类。在2015年到2017年之间,OpenAI主要进行人工智能研究和开发,并发布了一些开源工具和研究成果。
变革点是在2017年,这一年,谷歌大脑团队推出了Transformer模型,成为当时最先进的大型语言模型,对后来的人工智能发展产生了深远影响。
不过搞这个模型的团队,最开始可没想那么多,他们只是觉得当时的机器翻译太生硬了,所以想构建一个模型,能够理解整个句子的上下文,而不是仅将单个单词翻译成另一种语言。
这个理解句子的核心原理就是Transformer模型的自注意机制。
还是举个例子。
有这么一句英文:”The animal didn’t cross the street because it was too tired.”(翻译是:这种动物没有过马路,因为它太累了)
以前的翻译就是一个词一个词的搞呗,反正每个英文单词都有对应的汉语解释。但是这种方式对句子里面的一些代词可就非常不友好了。比如上面句子里面的“it”,在这里面可是专指“animal”,而不是在它前面的“street”。
这时候Transformer模型的自注意机制就刚好派上用场。
首先,自注意机制把句子中的每个单词被转换成一个固定维度的嵌入向量。也就是记录了每个单词所在的位置。
然后,模型会计算每个单词对于句子中其他所有单词的注意力权重。例如:
对于单词“it”,模型会计算它与“animal”、“cross”、“street”和“tired”的注意力权重。
由于“it”是句子的主语并且与“animal”有很强的联系,模型会给予“it”和“animal”之间的注意力较高的权重。
同时,模型也会识别出“it”与“tired”之间的联系,因为“it was too tired”是一个完整的从句,表明“it”是“tired”的主语。
这样,经过自注意力层和后续的神经网络层处理后,每个单词都被转换成一个高维空间中的向量,这些向量包含了整个句子的上下文信息。也就是说,Transformer模型能够知道这句话中词与词的关系。重点注意啊,这并不是人类对语言的那种理解,还是只属于数据关联的范畴。
OpenAI公司敏锐地捕捉到了Transformer模型的巨大潜力,因此迅速展开了基于这一模型的研发工作。他们深知,这一模型的出现将极大地推动自然语言处理领域的发展,未来的人工智能很有可能会上一个台阶。
2018年,OpenAI推出了具有1.17亿个参数的GPT-1模型,这一事件标志着自然语言处理领域的一大进步。GPT-1模型是OpenAI使用Transformer架构进行语言模型设计的第一次迭代。
这里的1.17亿个参数指的是模型在训练过程中需要学习和调整的内部变量。这些参数用于控制模型的行为,以便在给定输入时产生相应的输出。在前面所讲的深度学习中,模型通常由多个神经网络层组成,每个层都有许多神经元,而每个神经元都有与之关联的权重和偏置等参数。
GPT-1模型拥有如此多的参数,是因为它需要处理自然语言的任务太复杂了。通过调整这些参数,模型可以学习语言的语法、语义和上下文信息,从而生成流畅、连贯的文本。
2019年,OpenAI公布了具有15亿个参数的GPT-2模型,这是GPT系列模型的第二个版本,相较于前代GPT-1模型,GPT-2在规模和能力上都有了显著的提升。
尽管GPT-2模型取得了显著的进步,但OpenAI最初并没有向公众开放模型的全部代码及数据。这主要是担心被滥用生成一些虚假信息、恶意内容等。过了一段时间,OpenAI才逐渐开放了GPT-2模型的部分代码和数据,并为一些合作伙伴提供了访问权限。
2020年,OpenAI推出了一款具有划时代意义的语言模型——GPT-3。这款模型拥有惊人的1750亿个参数,这一数字远超过了其前身GPT-2的15亿个参数,使其在语言关联和生成能力上达到了前所未有的高度。GPT-3的推出,不仅彰显了OpenAI在自然语言处理领域的领先技术实力,也为整个AI行业树立了新的里程碑。
2022年11月底,OpenAI发布了基于GPT-3.5系列大型语音模型微调而成的全新对话式AI模型——ChatGPT。这一发布在人工智能和自然语言处理领域引起了广泛的关注和讨论。
ChatGPT的发布标志着自然语言处理技术迈向了新的里程碑。该模型不仅继承了GPT-3.5的强大能力,还在此基础上进行了微调,使其更加专注于对话式交互。通过深度学习技术,ChatGPT基本做到了可以与人类进行自然而流畅的对话。

以上就是ChatGPT一个概要的历史,实际上更多的讲了一些ChatGPT底层实现的技术。
现在有不少人都在鼓吹,ChatGPT来啦,AI马上要顶替绝大多数人的工作了啊,大家赶紧来买AI课,不会运用AI,注定要被时代淘汰。
然后还有不少小作文推波助澜,什么“时代抛弃你的时候,连声招呼都不打”、“潮水退去,才知道谁在裸游”布拉布拉之类的。搞得大家一阵紧张。
我要在这里明确的说,ChatGPT有用么?真的有用,而且确实是一个很好的产品。但是不要紧张,它替代不了谁,也革不了谁的命。它的核心原理就放在这儿,所以能干的事情,擅长干的事情也是一目了然,距离人的思维还差远。
比如,我对ChatGPT说一句:你好啊。它回答“您好,有什么可以帮助到您的”。
背后的技术过程是这样的:
首先,ChatGPT将所输入文本“你好啊”转换成一个序列的形式,通常是一个由数字表示的token序列。每个token通常对应一个单词或字符。(就是前面讲过的记录位置)
然后,序列通过Transformer模型的编码器部分,编码器利用自注意力机制处理输入序列,并生成一个包含上下文信息的高维向量表示。
接下来,模型的解码器开始生成回复。解码器在每一步都会输出一个概率分布,这个分布覆盖了所有可能的下一个token。初始阶段,这个概率分布是针对起始token的。在之后的每一步,解码器会考虑当前的上下文和已经生成的token序列,计算下一个token的概率分布。这个概率分布是通过模型的内部权重和激活函数计算得出的。
当解码器生成一个结束token,这表示响应已经完成。每一步生成的token都依赖于前一步的输出和整个输入序列。最后,生成的token序列经过转换,变回可读的文本形式,形成ChatGPT的回复“您好,有什么可以帮助到您的”。
上面过程翻译成大白话就是,ChatGPT看到了“你好啊”这个文本,然后就找到一个概率最高的回应语句的第一个字“您”,随后结合“你好啊”这个文本以及刚刚找到的“您”这个字再去找概率最高的下一个字“好”,如此反复,就得到了“您好,有什么可以帮助到您的”。(当然,这里做了简化解释,在Transformer模型生成回复的过程中,不是简单地一次只找到一个字,而是在每一步都计算下一个token的概率分布,这里的token可以是任意长度的词或字符)
所以ChatGPT的内核就是概率啊。

既然是概率,那就肯定有出错的可能性,而且这种出错是没有任何原因的,纯纯的就是随机事件,因此,对安全要求高的岗位就别考虑替换的这个事情,不现实。
比如说电力系统的调度。电力系统的调度对安全性的要求非常高,电力系统的稳定性和可靠性直接影响到社会经济活动和人们的生活质量。一旦调度出错,可能导致停电、设备损坏甚至更严重的后果。ChatGPT的出现带动国内各种大模型火的时候,也有公司要去搞大模型智能调度的,这个意义就不大了,基本上最后就是一个摆设。也有人说可以用于调度员的辅助工具、数据分析、预测预警等等方面啊。其实这个难度也很大,这些都有专门的算法研究的,你一个通用的东西怎么可能PK过那些只针对一个点搞了很多年的专业算法。
再说其他岗位。
比如程序员,现在唱衰这个行业的人可不少,反正大概的意思就是用AI写代码就好了啊,保质保量,还不会天天跟产品墨迹要砍需求。
真正写代码的人,对这种说法基本都是不屑一顾的。编程序的核心是什么?行外人觉得不就是噼里啪啦撸码嘛,还能有啥。还真不是。编程序的核心是理解代码(包括读懂一些屎山代码)、需求变更以及BUG修复。至于写代码,虽然花的时间很多,但是反而是自己最能把控的。
前面说过了啊,ChatGPT的内核是概率。也就是说,它写的代码里面肯定会有BUG的(越长的代码出BUG的概率越高)。这是不是需要自己去修复,但是要想修复这些BUG,是不是又要读懂代码,那谁来读懂这些代码呢?是被顶替岗位的程序员,还是那些唱衰这个行业的人?
最后说ChatGPT的专业最对口的岗位,写文案的文员。
在文案创作的岗位上,ChatGPT这类AI工具虽然具备强大的文本生成能力,但无法完全替代专业的文案文员。文案文员不仅要有扎实的文字功底,还需要深入理解品牌理念、目标受众和市场需求,通过细腻的笔触和巧妙的构思,将品牌故事、产品特点、营销策略等融入字里行间。这种对人文情感、市场洞察和创意思维的综合要求,是ChatGPT搞不定的啊。
总结起来说,ChatGPT实际上可以作为一个更好用的搜索引擎,给自己的工作减轻一些压力,最直接的就是周报让它来写就好了。