自ChatGPT发布以来,中国大模型产品距离ChatGPT有多远,始终是AI行业内最为关心的一个话题。如今,这个问题可能有了答案。
1月16日,在2024智谱AI技术开放日Zhipu DevDay上,CEO张鹏发布了新一代基座大模型GLM-4,性能接近GPT-4的90%。
过去一年里,智谱AI几乎每3-4个月就完成一次基座大模型的升级。GLM-4的发布,是智谱AI在去年10月发布ChatGLM3三个月后,又一次完成基座大模型的升级。
作为国内最早入局大模型技术的公司,也是大模型迭代最快的公司之一,智谱AI曾在2023年初设立了一个雄心勃勃的目标:用一年的时间追平OpenAI最先进的模型。
从目前看,智谱AI距离这个目标越来越近了。
/ 01 / GLM4等于90%的“GPT-4”
去年10月,智谱AI发布了ChatGLM3,并让人印象深刻。最直观的表现就是ChatGLM3 “疯狂屠榜”,所有50个大模型公开性能测评数据集中,拿下44个全国第一。
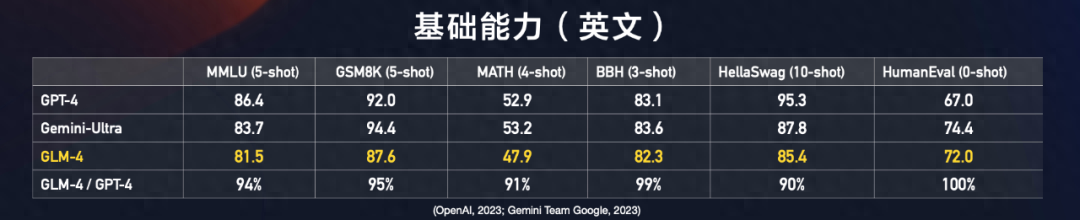
相比上一代ChatGLM3,GLM-4性能也有了明显提升。先说基础能力,在MMLU、GSM8K、BBH、MATH、HellaSwag、HumanEval数据集指标上都接近了GPT-4 90%以上。
那么,这些数据集分别代表什么能力呢?
MMLU全称是测量大模型多任务下的语言理解能力,里面包含了基础数学,历史,法律等共57个方面的题目,难度从高中到大学不等。目前,GLM4是81.5分,GPT4是86.4分,目前能达到GPT4的94%。
GSM8k 和 MATH 则是评估大型语言模型数学能力的标准基准,两者在难度上有所差异。前者GLM4能到GPT4的95%,后者GLM4只能达到GPT4的91%。
BBH是一个典型的推理型数据集,涵盖翻译、语言理解、逻辑推理等任务,这方面GLM4几乎能够与GPT4打平。
HellaSwag则是一个测试常识推理的测试,对人类来说很容易(~95%),但对最先进的模型来说却具有挑战性。在这点上,GLM4只能到GPT4的90%。
HumanEval 则是由 OpenAI 编写发布的代码生成评测数据集,主要是评测大模型在算法、代码、编程层面的效果。这是GLM4的强项,和GPT4在一个水平。可以说,以上的指标涵盖了大模型在语言理解、数学能力等多种能力。从基础能力角度上说,GLM4的能力差不多与90%的“GPT-4”相当。
第二项能力是指令跟随能力(中英),顾名思义这是考验模型对用户Prompt和Instruction的理解能力。在这一点上,GLM4的能力在GPT4的85%-90%之间。考虑到GPT4现有的语义理解和吃Prompt的能力,这样的表现也算不上差。
而在中文的能力上,GLM4的表现基本全面超过GPT4。当然,这背后很重要的一个原因是,GPT4训练的中文语料有限,而GLM4在这方面具备天然的优势。

第三个能力是LongBench,这是考验大模型的长文理解能力。此前,ChatGLM曾被人诟病处理长对话时上下文理解得不好、记忆力差。但后来,GLM 技术团队开发了专门针对模型长文本理解能力的评测数据集 LongBench。从目前看,GLM4在这个能力上已经超过了GPT4。
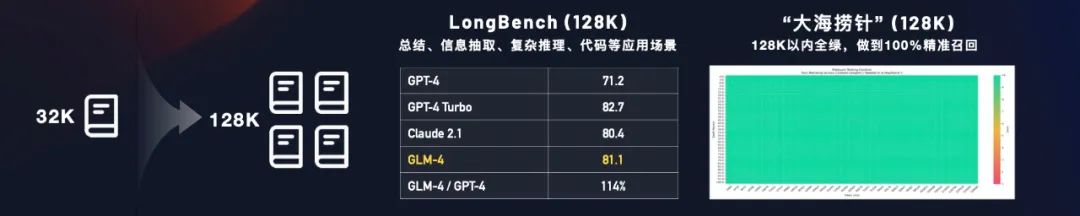
至于”大海捞针”测试,更像是对大模型在长文理解上的一次压力测试,128K相当于300页左右的PDF材料。
测试的目的是评估大模型从大量文本中检索信息的能力,特别是当信息被放置在文档的不同位置时的准确率。横轴表示上下文长度,纵轴表示文档深度的百分比,也就是要表达的信息(事实)被放置在整个文档中的位置,如果信息在文档的正中间,那么它的文档深度接近50%。
GLM4的”大海捞针”全绿,说明即使你扔给它一部300页的小说,它也能够精准找到想要信息。此前,有人给Claude2.1做过类似测试,在130K的文章长度上测试在35 个不同的文档深度,结果Claude2.1能取回结果的不到一半。这也一定程度上说明了GLM4在长文理解上的模型能力。
通过以上种种不难说明,GLM4在文本理解、指令跟随、长文理解等多项能力上都表现出了接近GPT4的能力。
/ 02 / 紧跟OpenAI脚步,ALL Tools和GLMs相继上线
除了基础能力的测评,智谱AI还上线了All Tools模式和GLMs。
什么是All Tools?这是OpenAI最早推出的模式,是在GPT4的基础上,把其他各种功能模块统一接入了,只需选择一个模型就能支持GPT4对话、高级数据分析(代码解释器)、多模态(图片分析)、DALLE3绘画、联网等功能,支持直接上传Excel、PDF、图片等文件来关联对话,会根据需要自动调用不同模式的功能。
在这个模式前,GPT4各个主要功能分散在不同的渠道、泾渭分明。比如,你想把一张照片,用 DALL-E 重新绘图,你需要首先把你的照片传给“多模态模式“,让它描述照片的内容,然后你到 DALL-E 输入提示词。
但随着All Tools的推出,整合工具后的 GPT-4 不再需要切换即可使用所有的功能。也就是说,GPT4 将根据你给的指令理解你的意图,自动选择并串联多个工具完成任务。
更重要的是,All Tools也被认为形成一个小型Agent的前提。而如今,智谱是国内第一个真正推出ALL Tools模式的公司。
不仅如此,智谱也正式上线了他们的GLMs。不久前,OpenAI上线了GPTs,用户甚至不需要会编程,仅通过对话聊天方式,就打造一个专属个性化的GPT,用户可以将它设计为私人使用,也可以专门给公司内部使用,或者通过「GPT商店」赚钱。
在很多人看来,GPTs可以理解为大模型领域的苹果“App Store”,其价值在于给了大家更多创造基于GPT技术应用和服务的机会,让其后续构建基于AI新的经济生态变成了可能,并有望打破AI商业化的难题。
这可能也是智谱上线了GLMs的考虑。与GPTs类似,用户同样可以在GPTs创建智能体,甚至分享给其他用户。智谱表示,公司即将公布GLMs创作者分成计划。
不过与GPTs不同,GLMs的页面上没有搜索,只有官方推荐。当然,这个可能功能与处于早期,智能体数量较少有很大关系。
从底层技术测评到ALL Tools和GLMs等功能的相继上线,种种迹象显示,智谱AI正在离中国Open AI越来越近了。
/ 03 / 摸着OpenAI过河
在中国AI产业里,智谱AI是一个不可不提的名字。因为这可能国内“百模大战”中估值最高的明星大模型公司,没有之一。
2023年10月,智谱AI宣布完成超25亿人民币融资,投资方汇聚了国内一线明星机构,包括社保基金中关村自主创新基金(君联资本为基金管理人)、美团、蚂蚁、阿里、腾讯、小米、金山、顺为、Boss直聘、好未来、红杉、高瓴等。这样的股东阵容不可谓不豪华。
投资人纷纷押注智谱AI的逻辑很简单,智谱AI是最早研发大模型的企业之一。
智谱AI的前身,是在2006年诞生于清华大学计算机系知识工程实验室(KEG)的明星产品AMiner——学术搜索与情报挖掘平台。清华大学教授、KEG主任唐杰,是AMiner的核心创立者之一。
2019年,清华大学教授李涓子、唐杰等人依托AMine为基础,共同成立智谱AI,公司CEO由张鹏担任,他是国内首个中英文平衡的跨语言知识图谱系统XLORE的设计和研发者。2020年,OpenAI发布GPT-3,让张鹏认识到大模型将成为未来的方向。于是,刚成立一年的智谱AI开始全力投入大模型的研发。
回过头来看,提前3年的“抢跑”,让智谱AI有更多的技术底气。时至今日,智谱AI在Hugging Face上的下载量超过1100万次,位居全球最受欢迎开源机构第五名,也是国内唯一上榜的公司;其对话模型ChatGLM在GitHub上获得了5万+颗星,超过Llama。
正如很多投资人所说,历史上没有哪个赛道能够像这波 AI 一样,迅速建立极大的共识。相比于应用端的不确定性,投资人更愿意抱团底层大模型玩家。而拥有技术储备的智谱AI就成为所有人的最优选择。
从目前看,智谱AI的发展策略也很清晰——摸着OpenAI过河。在国内,智谱AI可以说是唯一一家全系对标OpenAI的公司。这也在此次发布会中体现得淋漓尽致。
对于智谱AI来说,这不失为一种好的策略。在大模型商业化前景尚不清晰的当下,坐拥着国内一线明星机构的资源和背书,在中国AI产业的追赶进程中,扮演好最接近OpenAI的角色,能够让智谱AI在相当长的时间里成为站在舞台中央的那个“明星”。