“取消今晚所有计划!”,许多AI开发者决定不睡了。
只因首个开源MoE大模型刚刚由Mistral AI发布。
MoE架构全称专家混合(Mixture-of-Experts),也就是传闻中GPT-4采用的方案,可以说这是开源大模型离GPT-4最近的一集了。
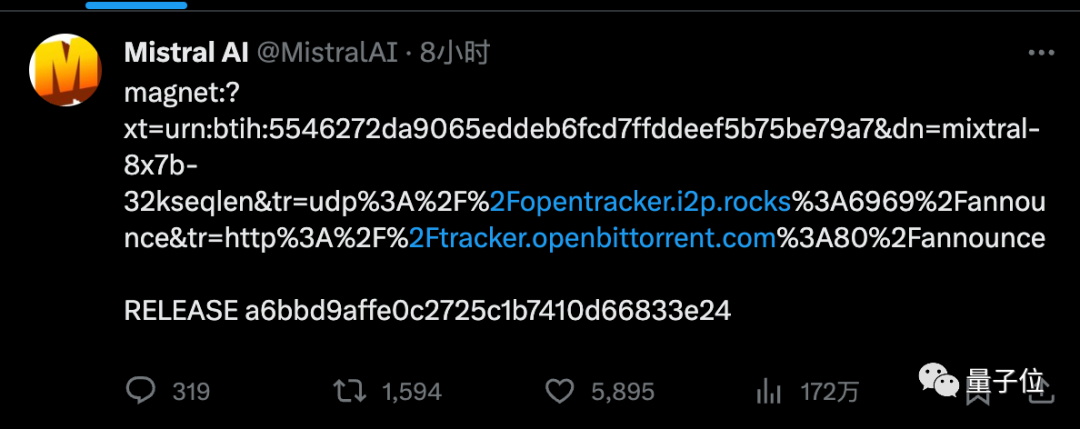
没有发布会、没有宣传视频,只靠一个磁力链接,就产生如此轰动效果。
具体参数还得是网速快的人下载完之后,从配置文件里截图发出来的:
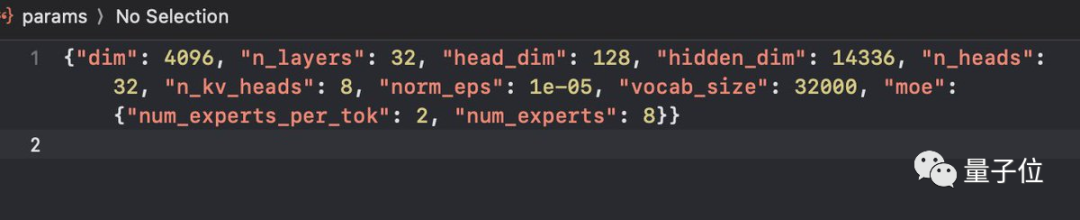
7B参数x8个专家,对每个token选择前两个最相关的专家来处理。
以至于OpenAI创始成员Karpathy都吐槽,是不是少了点什么?
怎么缺了一个那种排练很多次的专业范视频,大谈特谈AI变革啊。
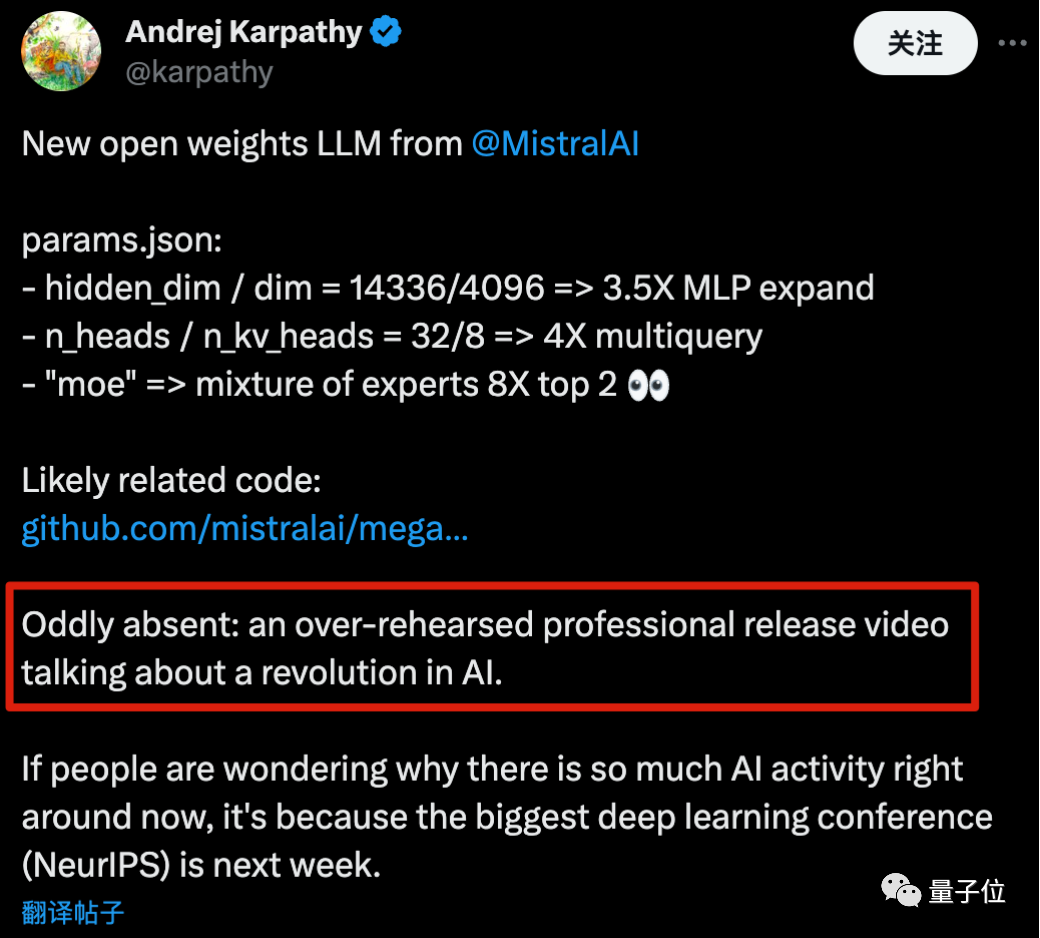
至于吐槽的是谁,懂得都懂了。
以及他还解释了为什么AI社区这几天如此活跃:最大的深度学习会议NeurIPS即将在下周开启。
MoE,开源大模型新阶段?
为何这款开源MoE模型如此受关注?
因为其前身Mistral-7B本来就是开源基础模型里最强的那一档,经常可以越级挑战13B、34B。
并且Mistral-7B以宽松的Apache-2.0开源协议发布,可免费商用,这次新模型很可能沿用这个协议。
在多个评测排行榜上,基于Mistral-7B微调的Zephyr-7B-beta都是前排唯一的7B模型,前后都是规模比他大得多的模型。
LLMSYS Chatbot Arena上,Zephry-7B-beta目前排第12。