近日,大模型领域引发了巨大的关注。一张表格在微软的论文中,似乎泄露了一个巨大的秘密。这张表格揭示了ChatGPT的模型参数仅为200亿,这一消息瞬间成为了焦点。

聊天机器人ChatGPT近期已经成为了技术界的明星。因此,这一揭示的消息在国内外迅速传播。许多人甚至开始质疑:这真的是正确的吗?可能是一个打字错误?但事实似乎确实如此。

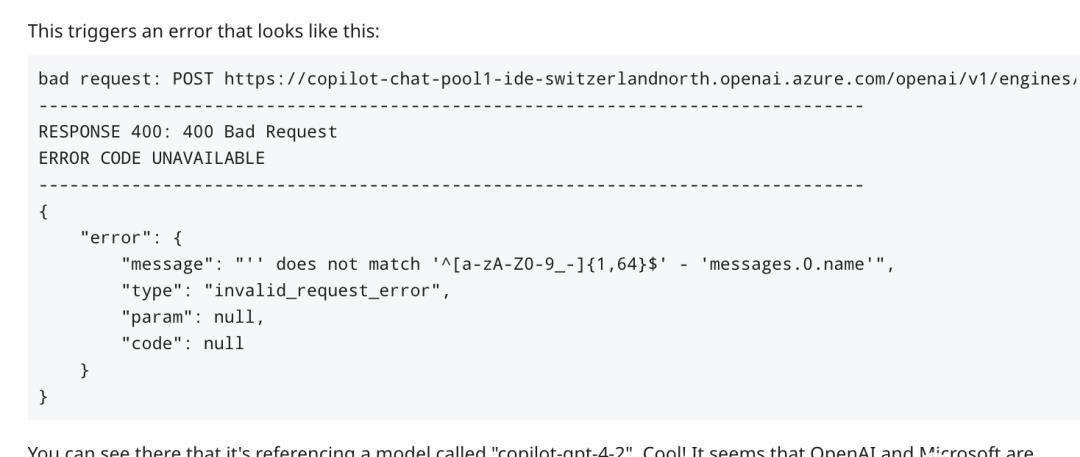
此外,有越来越多的人认为这是OpenAI即将开源的前奏。尤其是考虑到GitHub Copilot的API最近被发现有GPT-4的新版本,其数据更新已经到了2023年3月。

那么,这篇论文除了这些令人震惊的消息还讲了什么呢?这篇论文并非仅仅关于参数的数量。微软研究团队也在其中提到了扩散模型用于代码生成的先进性。这种模型考虑了一个特定的场景,即开发人员只能修改最后一行代码,那么从头开始编写一个函数需要多少次尝试?微软的研究员介绍了一种名为CODEFUSION的编码-解码架构。它将自然语言编码为连续表示,然后在扩散模型中进行迭代去噪。而为了生成准确的代码,它在解码之后还有一个去噪的步骤。
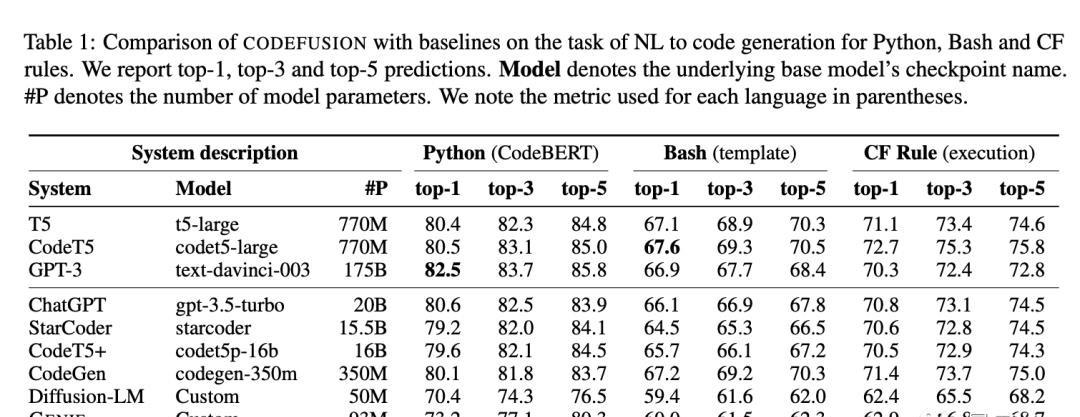
这种技术被评估在多种语言上,例如Python、Bash和Excel条件格式化规则。最令人震惊的是,这种只有7500万参数的模型与拥有200亿参数的GPT-3.5-turbo的性能相近,而且还能生成更加多样化的代码。

CODEFUSION与其他技术相比也显示出了它的优势。与纯文本生成的扩散模型相比,它能生成更多的语法正确代码。而与自回归模型相比,它能生成更加多样化的代码。
事实上,与当前最先进的自回归系统相比,CODEFUSION在代码生成的准确性上都能够匹敌,甚至在某些方面还超过了它。

这篇论文原本只是一篇普通的性能比较,但现在已经成为了焦点。有人认为这是OpenAI即将开源的前奏,也有人质疑其背后的动机。

早在今年2月,福布斯就已经曝光了ChatGPT只有200亿参数的消息。只是当时没有引起太多关注。
总的来说,这篇论文不仅揭示了ChatGPT的参数数量,还展示了一种新颖的代码生成技术。这两者都为大模型领域带来了巨大的关注。而在这背后,或许还隐藏着更多的秘密和故事。


大模型引发的瞩目近期,大模型领域的关注度急剧上升,尤其是ChatGPT成为了技术界的明星。微软的论文揭示了ChatGPT的模型参数仅有200亿,这一消息在国内外引起轰动。人们纷纷质疑其真实性,这个数字是否有误。这个巨大的关注度表明了大型语言模型在科技领域的重要性,以及人们对其性能和规模的极大兴趣。

开源的可能性与技术进展此消息也引发了人们对OpenAI是否将开源这一模型的猜测。尤其是考虑到GitHub Copilot的API中出现了GPT-4的新版本,数据更新截止到了2023年3月。这表明了ChatGPT的性能和规模可能是一个前奏,将来可能会对更多开发者开放。这也展示了技术领域的不断进步,模型性能的提升和开源的可能性将推动更多创新和应用的出现。
CODEFUSION的革命性微软论文中提到的CODEFUSION技术是一个革命性的代码生成技术。它将自然语言编码为连续表示,然后通过迭代去噪的方式在扩散模型中生成准确的代码。与传统的扩散模型和自回归模型相比,CODEFUSION能够生成更多语法正确和多样化的代码,甚至在某些方面超越了自回归系统。这项技术为代码生成领域带来了巨大的潜力和创新,对于开发者和编程社区来说,这是一个重要的进步。
CODEFUSION的革命性微软论文中提到的CODEFUSION技术是一个革命性的代码生成技术。它将自然语言编码为连续表示,然后通过迭代去噪的方式在扩散模型中生成准确的代码。与传统的扩散模型和自回归模型相比,CODEFUSION能够生成更多语法正确和多样化的代码,甚至在某些方面超越了自回归系统。这项技术为代码生成领域带来了巨大的潜力和创新,对于开发者和编程社区来说,这是一个重要的进步。