当地时间9月20日,人工智能开发机构OpenAI向一小群测试人员发布了图像生成器DALL·E的新版本,并将这项技术整合到聊天机器人ChatGPT中。实际上,DALL·E 3本身就以ChatGPT为基础构建。根据OpenAI官网消息,DALL·E 3将于10月初向ChatGPT Plus(每月20美元费用)和企业客户提供。

提示词:满月下的街道,熙熙攘攘的行人正在享受繁华夜生活。街角摊位上,一位有着火红头发、穿着标志性天鹅绒斗篷的年轻女子,正在和脾气暴躁的老小贩讨价还价。这个脾气暴躁的小贩身材高大,老道,身着一套整洁西装,留着引人注目的小胡子,正在用他那部蒸汽朋克式的电话兴致勃勃地交谈。图片来源:DALL·E 3
DALL·E的名称来自于艺术家萨尔瓦多·达利(Salvador Dalí)和《机器人总动员》的主角WALL-E,第一版于2021年1月首次亮相,第二版发布于2022年4月。
OpenAI此前也提供了将ChatGPT与其他在线服务连接的方式,包括酒店机票预订程序Expedia、餐厅预订程序OpenTable和维基百科Wikipedia,但这是其首次将自己最强大的语言模型与最强大的文生图模型结合在一起,一方面极大降低了提示词的专业门槛,另一方面对语言的细微之处有了很好展现。
特别擅长生成人类手部图像
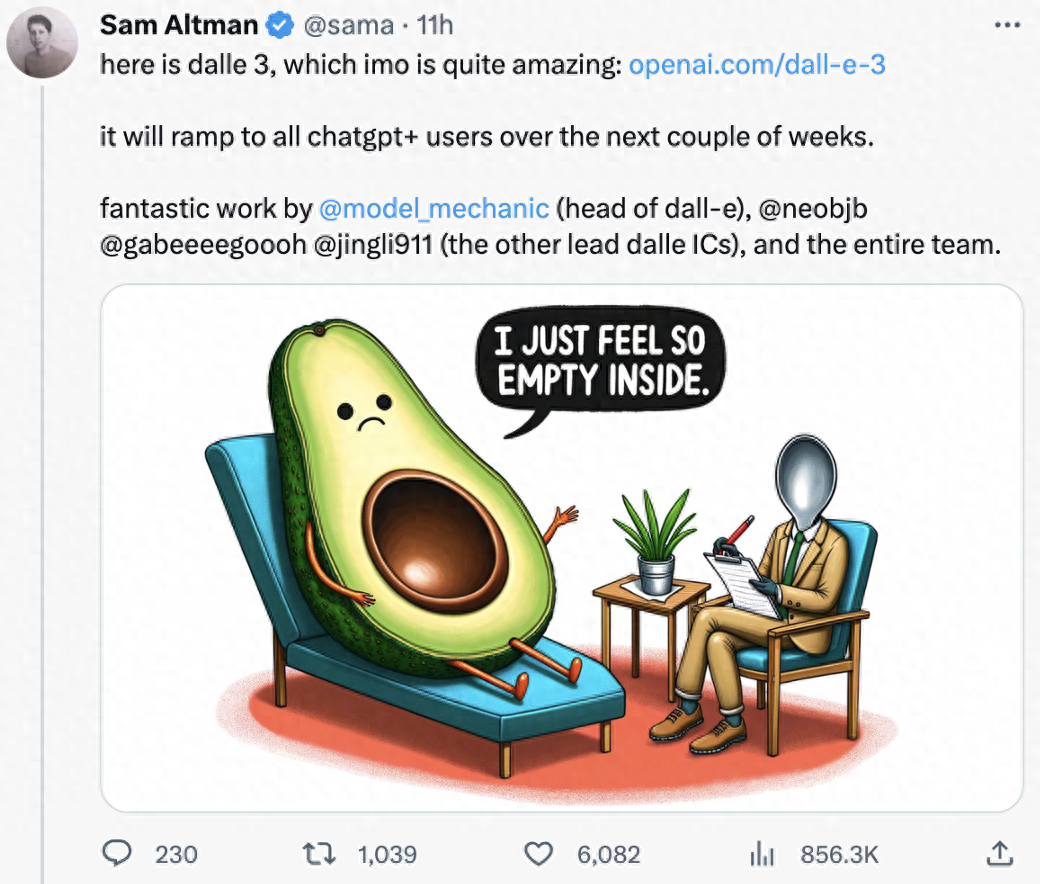
提示词:一个牛油果坐在治疗师的椅子上,说着“我只是觉得内心空虚”,中心有一个坑洞大小的果核。治疗师是一把勺子,正在匆匆记录笔记。
OpenAI首席执行官山姆·奥特曼(Sam Altman)在X(前身推特)上单独展示了两幅图,其中一个是“牛油果看医生”,提示词是:一个牛油果坐在治疗师的椅子上,说着“我只是觉得内心空虚”,中心有一个坑洞大小的果核。治疗师是一把勺子,正在匆匆记录笔记。
在这条帖子下,有热心网友在DALL·E 2上尝试了同样的提示词。可以发现其基本看不出治疗师的椅子,坑洞也没有清晰展现,治疗师更是没有。
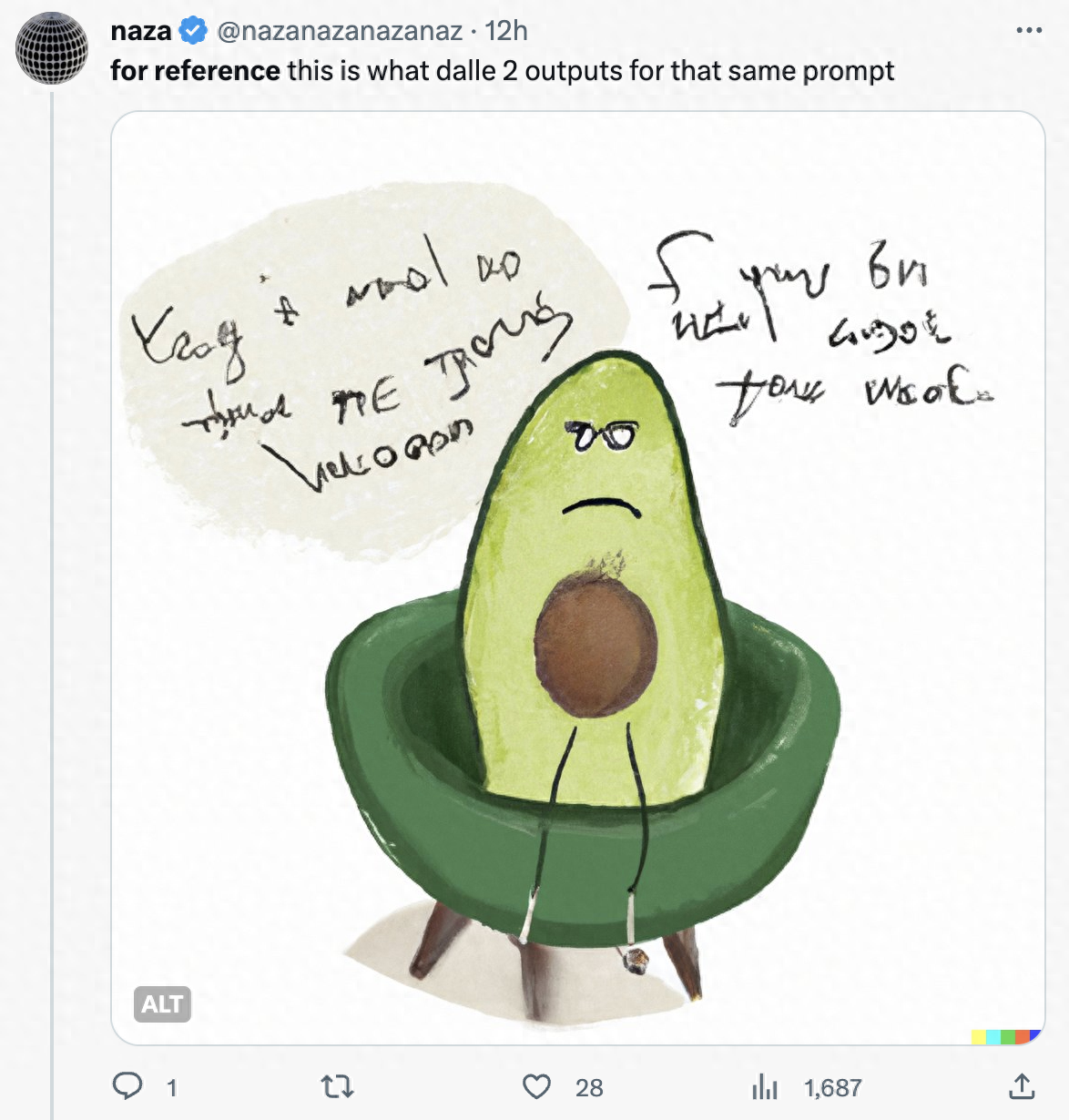
“牛油果看医生”。图片来源:DALL·E 2
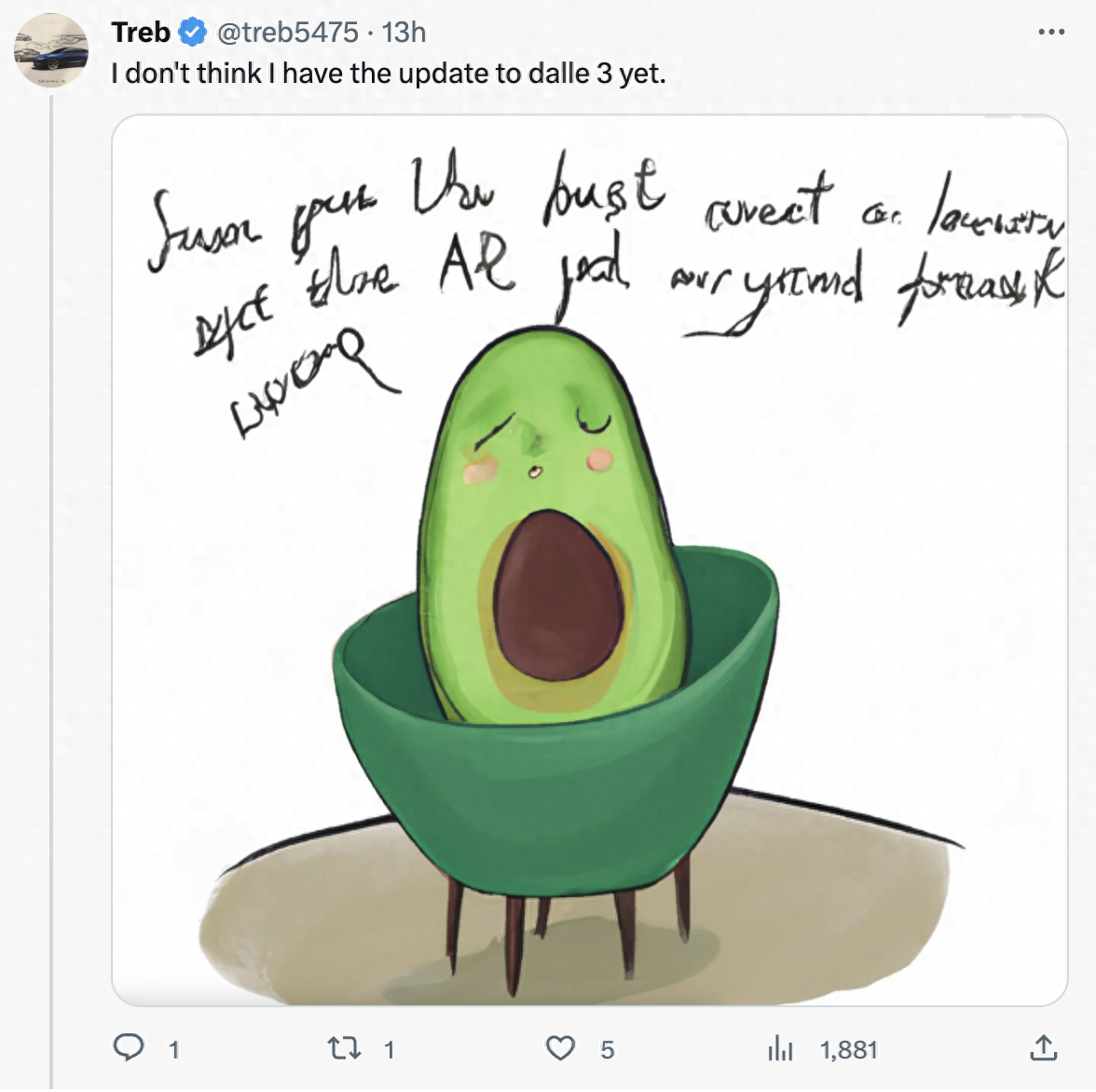
“牛油果看医生”。图片来源:DALL·E 2
在官网上,OpenAI也贴心地给出了一组DALL·E 2(左)和DALL·E 3(右)的对比图,提示词为“一幅富有表现力的油画,描绘了一名扣篮的篮球运动员,呈现出星云的爆炸”。

图片来源:OpenAI官网
再对比最初版本的DALL·E,则可看出在这一两年的时间,OpenAI走了多远。以下是第一版DALL·E根据文字“牛油果型的扶手椅”自动创作的部分图像。

根据文字“牛油果型的扶手椅”生成图像。图片来源:DALL·E
据OpenAI介绍,DALL·E 3的版本比先前的版本能够生成更具说服力的图像,它特别擅长生成包含字母、数字和人类手部的图像,而人类手部的图像生成一直是这一领域的一个技术难点。

提示词:一名亚洲血统的中年女性,她的黑发上夹杂着银色条纹,看上去已经断裂、破碎、错综复杂地镶嵌在一片碎瓷片海洋中。瓷器上闪烁着泼彩图案,有光泽的和哑光的蓝色、绿色、橙色和红色和谐地融合,以超现实的动静结合的方式捕捉到了她的舞蹈。她的肤色像瓷器一样浅,给她的身材增添了一种近乎神秘的品质。图片来源:DALL·E 3
据介绍,DALL·E 3的巨大飞跃主要体现在两大方面。第一,只需要提示词,ChatGPT可自动对词语进行拓展,极大地弱化了提示工程的约束,生成图画细节更多、描述更精准;第二,因为ChatGPT原生,模型在理解用户指令及将文本转化为图片的能力增加了。OpenAI表示,DALL·E 3比以往系统更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确的图像。
英伟达高级人工智能科学家范吉姆(Jim Fan)在X上表示,我认为DALL·E 3不仅仅是应对MidJourney的竞争。实际上,它是对即将到来的大规模多模态语言模型之间的史诗级对抗,以及与DeepMind的Gemini之间竞争的预演。据谷歌旗下DeepMind CEO戴密斯·哈萨比斯(Demis Hassabis)在最近的采访中透露,一旦Gemini上市,它将比OpenAI的 ChatGPT更强大。
自从去年ChatGPT走红以来,硅谷科技巨头之间已经展开了一场争夺领先位置的人工智能竞赛。谷歌在最近发布了聊天机器人Bard的新版本,将其与谷歌最受欢迎的几项服务如Gmail、YouTube和Docs连接起来。Midjourney和Stable Diffusion等其他图像生成器也在今年夏天更新了模型。
范吉姆认为,“DALL·E 3是在ChatGPT的基础上本地构建的”,是OpenAI关于DALL·E 3的介绍中非常关键的一句话。DALL·E 3的卓越语言对齐能力是建立在坚实的文本GPT基础之上的,MidJourney实际上没有太多的推理大脑,这就是为什么需要大量的提示词。“首先是‘大脑’,其次才是像素——这是构建强大多模态人工智能的方式。”范吉姆写道。
图像生成技术引发安全担忧
“最新版本的DALL·E可以根据多段描述生成图像,并且可以详细遵循分钟级别的指示。”OpenAI研究员加布里埃尔·吴(Gabriel Goh)说。但他也表示,与所有图像生成器和其他人工智能系统一样,它也容易出错。
专家警告称,图像生成技术可以用于在网络上传播大量虚假信息。为了防范DALL·E 3出现这种情况,OpenAI已经整合了旨在防止问题图像的工具,其还试图限制DALL·E模仿特定艺术家风格的能力。
最近几个月以来,人工智能已被用作视觉虚假信息的来源。5月,一张关于五角大楼爆炸的虚假图片引发了股市的短暂下跌,这只是其中一个例子。

一张关于五角大楼爆炸的AI生成虚假图片。
《纽约时报》报道称,专家还担心,在重大选举期间,这项技术可能被用于恶意目的。专注于安全和政策的OpenAI研究员桑迪尼·阿加瓦尔(Sandhini Agarwal)表示,DALL·E 3倾向于生成风格化而非真实感的图像,但该模型也可以被激发生成像真实图片的场景,例如安保摄像机拍摄的颗粒状图像类型。
在大多数情况下,OpenAI并不打算阻止DALL·E 3 生成潜在可能产生问题的内容。阿加瓦尔表示,这种方法“过于宽泛”,因为图像可能是无害的,也可能是危险的,具体取决于它们出现的上下文。她说,这种方法“完全取决于它的使用方式,以及人们如何谈论它”。